
Software Development as Advanced Damage Control
The reason software isn't better is because it takes a lifetime to understand how much of a mess we've made of things, and by the time you get there, you will have contributed significantly to the problem.

The fastest code is code that doesn't need to run, and the best code is code you don't need to write. This is rather obvious. Less obvious is how to get there, or who knows. Every coder has their favored framework or language, their favored patterns and practices. Advice on what to do is easy to find. More rare is what not to do. They'll often say "don't use X, because of Y," but that's not so much advice as it is a specific criticism.
The topic interests me because significant feats of software engineering often don't seem to revolve around new ways of doing things. Rather, they involve old ways of not doing things. Constraining your options as a software developer often enables you to reach higher than if you hadn't.
Many of these lessons are hard learned, and in retrospect often come from having tried to push an approach further than it merited. Some days much of software feels like this, as if computing has already been pushing our human faculties well past the collective red line. Hence I find the best software advice is often not about code at all. If it's about anything, it's about data, and how you organize it throughout its lifecycle. That is the real currency of the coder's world.
Usually data is the ugly duckling, relegated to the role of an unlabeled arrow on a diagram. The main star is all the code that we will write, which we draw boxes around. But I prefer to give data top billing, both here and in general.
One-way Data Flow
In UI, there's the concept of one-way data flow, popularized by the now omnipresent React. One-way data flow is all about what it isn't, namely not two-way. This translates into benefits for the developer, who can reason more simply about their code. Unlike traditional Model-View-Controller architectures, React is sold as being just the View.
Expert readers however will note that the original trinity of Model-View-Controller does all flow one way, in theory. Its View receives changes from the Model and updates itself. The View never talks back to the model, it only operates through the Controller.

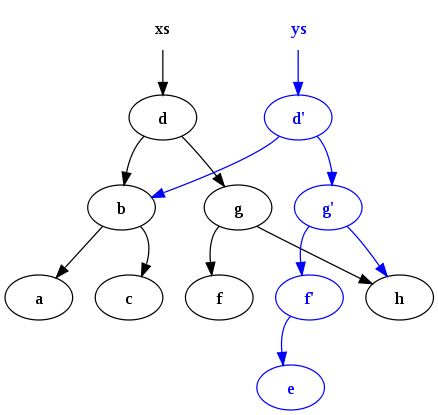
The reason it's often two-way in practice is because there are lots of M's, V's and C's which all need to communicate and synchronize in some unspecified way:

The source of truth is some kind of nebulous Ur-Model, and each widget in the UI is tied to a specific part of it. Each widget has its own local model, which has to bi-directionally sync up to it. Children go through their parent to reach up to the top.
When you flatten this, it starts to look more like this:

Between an original model and a final view must sit a series of additional "Model Controllers" whose job it is to pass data down and to the right, and vice versa. Changes can be made in either direction, and there is no single source of truth. If both sides change at the same time, you don't know which is correct without more information. This is what makes it two-way.

The innovation in one-way UI isn't exactly to remove the Controller, but to centralize it and call it a Reducer. It also tends to be stateless, in that it replaces the entire Model for every change, rather than updating it in place.
This makes all the intermediate arrows one-way, restoring the original idea behind MVC. But unlike most MVC, it uses a stateless function f: model => views to derive all the Views from the Ur-Model in one go. There are no permanent Views that are created and then set up to listen to an associated Model. Instead Views are pure data, re-derived for every change, at least conceptually.
In practice there is an actual trick to making this fast, namely incrementalism and the React Reconciler. You don't re-run everything, but you can pretend you do. A child is guaranteed to be called again if a parent has changed. But only after giving that parent, and its parents, a chance to react first.
Even if the Views are a complex nested tree, the data flow is entirely one way except at the one point where it loops back to the start. If done right, you can often shrink the controller/reducer to such a degree that it may as well not be there.
Much of the effort in developing UI is not in the widgets but in the logic around them, so this can save a lot of time. Typical MVC instead tends to spread synchronization concerns all over the place as the UI develops, somewhat like a slow but steadily growing cancer.
The solution seems to be to forbid a child from calling or changing the state of its parent directly. Many common patterns in old UI code become impossible and must be replaced with alternatives. Parents do often pass down callbacks to children to achieve the same thing by another name. But this is a cleaner split, because the child component doesn't know who it's calling. The parent can decide to pass-through or decorate a callback given to it by its parent, and this enables all sorts of fun composition patterns with little to no boilerplate.
You don't actually need to have one absolute Ur-Model. Rather the idea is separation of concerns along lines of where the data comes from and what it is going to be used for, all to ensure that change only flows in one direction.
The benefits are numerous because of what it enables: when you don't mutate state bidirectionally, your UI tree is also a data-dependency graph. This can be used to update the UI for you, requiring you to only declare what you want the end result to be. You don't need to orchestrate specific changes to and fro, which means a lot of state machines disappear from your code. Key here is the ability to efficiently check for changes, which is usually done using immutable data.
The merit of this approach is most obvious once you've successfully built a complex UI with it. The discipline it enforces leads to more elegant and robust solutions, because it doesn't let you wire things up lazily. You must instead take the long way around, and design a source of truth in accordance with all its intended derivatives. This forces but also enables you to see the bigger picture. Suddenly features that seemed insurmountably complicated, because they cross-cut too many concerns, can just fall out naturally. The experience is very similar to Immediate Mode UI, only with the ability to decouple more and do async.
If you don't do this, you end up with the typical Object-Oriented system. Every object can be both an actor and can be mutually acted upon. It is normal and encouraged to create two-way interactions with them and link them into cycles. The resulting architecture diagrams will be full of unspecified bidirectional arrows that are difficult to trace, which obscure the actual flows being realized.
Unless they represent a reliable syncing protocol, bidirectional arrows are wishful thinking.
Immutable Data
Almost all data in a computer is stored on a mutable medium, be it a drive or RAM. As such, most introductions to immutable data will preface it by saying that it's kinda weird. Because once you create a piece of data, you never update it. You only make a new, altered copy. This seems like a waste of perfectly good storage, volatile or not, and contradicts every programming tutorial.
Because of this it is mandatory to say that you can reduce the impact of it with data sharing. This produces a supposedly unintuitive copy-on-write system.
But there's a perfect parallel, and that's the pre-digital office. Back then, most information was kept on paper that was written, typed or printed. If a document had to be updated, it had to be amended or redone from scratch. Aside from very minor annotations or in-place corrections, changes were not possible. When you did redo a document, the old copy was either archived, or thrown away.
The perfectly mutable medium of computer memory is a blip, geologically speaking. It's easy to think it only has upsides, because it lets us recover freely from mistakes. Or so we think. But the same needs that gave us real life bureaucracy re-appear in digital form. Only it's much harder to re-introduce what came naturally offline.
Instead of thinking of mutable data as the default, I prefer to think of it as data that destroys its own paper trail. It shreds any evidence of the change and adjusts the scene of the crime so the past never happened. All edits are applied atomically, with zero allowances for delay, consideration, error or ambiguity. This transactional view of interacting with data is certainly appealing to systems administrators and high-performance fetishists, but it is a poor match for how people work with data in real life. We enter and update it incrementally, make adjustments and mistakes, and need to keep the drafts safe too. We need to sync between devices and across a night of sleep.

Girl With Balloon aka The Self-shredding Painting (Banksy)
Storing your main project in a bunch of silicon that loses its state as soon as you turn off the power is inadvisable. This is why we have automated backups. Apple's Time Machine for instance turns your computer into a semi-immutable data store on a human time scale, garbage collected behind the scenes and after the fact. Past revisions of files are retained for as long is practical, provided the app supports revision control. It even works without the backup drive actually hooked up, as it maintains a local cache of the most recent edits as space permits.
It's a significant feat of engineering, supported by a clever reinterpretation of what "free disk space" actually means. It allows you to Think Different™ about how data works on your computer. It doesn't just give you the peace of mind of short-term OS-wide undo. It means you can still go fish a crumpled piece of data out of the trash long after throwing banana peels and coke cans on top. And you can do it inline, inside the app you're using, using a UI that is only slightly over the top for what it does.
That is what immutable data gets you as an end-user, and it's the result of deciding not to mutate everything in place as if empty disk space is a precious commodity. The benefits can be enormous, for example that synchronization problems get turned into fetching problems. This is called a Git.
It's so good most developers would riot if they were forced to work without it, but almost none grant their own creations the same abilities.

Git repositories are of course notorious for only growing bigger, never shrinking, but that is a long-standing bug if we're really honest. It seems pretty utopian to want a seamless universe of data, perfectly normalized by key in perpetuity, whether mutable or immutable. Falsehoods programmers believe about X is never wrong on a long enough time-scale, and you will need affordances to cushion that inevitable blow sooner or later.
One of those falsehoods is that when you link a piece of data from somewhere else, you always wish to keep that link live instead of snapshotting it, better known as Database Normalization. Given that screenshots of screenshots are now the most common type of picture on the web, aside from cats, we all know that's a lie. Old bills don't actually self-update after you move house. In fact if you squint hard "Print to PDF" looks a lot like compiling source code into a binary for normies, used for much the same reasons.
The analogy to a piece of paper is poignant to me, because you certainly feel it when you try to actually live off SaaS software meant to replicate business processes. Working with spreadsheets and PDFs on my own desktop is easier and faster than trying to use an average business solution designed for that purpose in the current year. Because they built a tool for what they thought people do, instead of what we actually do.
These apps often have immutability, but they use it wrong: they prevent you from changing something as a matter of policy, letting workflow concerns take precedence over an executive override. If e.g. law requires a paper trail, past versions can be archived. But they should let you continue to edit as much as you damn well want, saving in the background if appropriate. The exceptions that get this right can probably be counted on one hand.
Business processes are meant to enable business, not constrain it. Requiring that you only ever have one version of everything at any time does exactly that. Immutability with history is often a better solution, though not a miracle cure. Doing it well requires expert skill in drawing boundaries between your immutable blobs. It also creates a garbage problem and it won't be as fast as mutable in the short term. But in the long term it just might save someone a rewrite. It's rarely pretty when real world constraints collide with an ivory tower that had too many false assumptions baked into it.

Parliamentary Archives at Victoria Tower – Palace of Westminster
Pointerless Data
Data structures in a systems language like C will usually refer to each other using memory pointers: these are raw 64-bit addresses pointing into the local machine's memory, obscured by virtualization. They reference memory pages that are allocated, with their specific numeric value meaningless and unpredictable.
This has a curious consequence: the most common form of working with data on a computer is one of the least useful encodings of that data imaginable. It cannot be used as-is on any other machine, or even the same machine later, unless loaded at exactly the same memory offset in the exact same environment.
Almost anything else, even in an obscure format, would have more general utility. Serializing and deserializing binary data is hence a major thing, which includes having to "fix" all the pointers, a problem that has generated at least 573 kiloyaks worth of shaving. This is strange because the solution is literally just adding or subtracting a number from a bunch of other numbers over and over.
Okay that's a lie. But what's true is that every pointer p in a linked data structure is really a base + i, with a base address that was determined once and won't change. Using pointers in your data structure means you sprinkle base + invisibly around your code and your data. You bake this value into countless repeated memory cells, which you then have to subtract later if you want to use their contents for outside purposes.
Due to dynamic memory allocation the base can vary for different parts of your linked data structure. You have to assume it's different per pointer, and manually collate and defragment all the individual parts to serialize something.
Pointers are popular because they are easy, they let you forget where exactly in memory your data sits. This is also their downside: not only have you encoded your data in the least repeatable form possible, but you put it where you don't have permission to search through all of it, add to it, or reorganize it. malloc doesn't set you free, it binds you.
But that's a design choice. If you work inside one contiguous memory space, you can replace pointers with just the relative offset i. The resulting data can be snapshotted as a whole and written to disk. In addition to pointerless, certain data structures can even be made offsetless.
For example, a flattened binary tree where the index of a node in a list determines its position in the tree, row by row. Children are found at 2*i and 2*i + 1. This can be e.g. used on GPUs and allows for very efficient traversal and updates. It's also CPU-cache friendly. This doesn't work well for arbitrary graphs, but is still a useful trick to have in your toolbox. In specific settings, pointerless or offsetless data structures can have significant benefits. The fact that it lets you treat data like data again, and just cargo it around wholesale without concern about the minutiae, enables a bunch of other options around it.

It's not a silver bullet because going pointerless can just shift the problem around in the real world. Your relative offsets can still have the same issue as before, because your actual problem was wrangling the data-graph itself. That is, all the bookkeeping of dependent changes when you edit, delete or reallocate. Unless you can tolerate arbitrary memory fragmentation and bloating, it's going to be a big hassle to make it all work well.
Something else is going on beyond just pointers. See, most data structures aren't really data structures at all. They're acceleration structures for data. They accelerate storage, querying and manipulation of data that was already shaped in a certain way.
The contents of a linked list are the same as that of a linear array, and they serialize to the exact same result. A linked list is just an array that has been atomized, tagged and sprayed across an undefined memory space when it was built or loaded.
Because of performance, we tend to use our acceleration structures as a stand-in for the original data, and manipulate that. But it's important to realize this is programmer lazyness: it's only justified if all the code that needs to use that data has the same needs. For example, if one piece of code does insertions, but another needs random access, then neither an array nor linked list would win, and you need something else.
We can try to come up with ever-cleverer data structures to accommodate every imaginable use, and this is called a Postgres. It leads to a ritual called a Schema Design Meeting where a group of people with differently shaped pegs decide what shape the hole should be. Often you end up with a too-generic model that doesn't hold anything particularly well. All you needed was 1 linked list and 1 array containing the exact same data, and a function to convert one to the other, that you use maybe once or twice.
When a developer is having trouble maintaining consistency while coding data manipulations, that's usually because they're actually trying to update something that is both a source of truth and output derived from it, at the same time in the same place. Most of the time this is entirely avoidable. When you do need to do it, it is important to be aware that's what that is.
My advice is to not look for the perfect data structure which kills all birds with one stone, because this is called a Lisp and few people use it. Rather, accept the true meaning of diversity in software: you will have to wrangle different and incompatible approaches, transforming your data depending on context. You will need to rely on well-constructed adaptors that exist to allow one part to forget about most of the rest of the universe. It is best to become good at this and embrace it where you can.
As for handing your data to others, there is already a solution for that. They're called file formats, and they're a thing we used to have. Software used to be able to read many of them, and you could just combine any two tools that had the same ones. Without having to pay a subscription fee for the privilege, or use a bespoke one-time-use convertor. Obviously this was crazy.
These days we prefer to link our data and code using URLs, which is much better because web pages can change invisibly underneath you without any warning. You also can't get the old version back even if you liked it more or really needed it, because browsers have chronic amnesia. Unfortunately it upsets publishers and other copyright holders if anyone tries to change that, so we don't try.

Squeak/SmallTalk
Suspend and Resume
When you do have snapshottable data structures that can be copied in and out of memory wholesale, it leads to another question: can entire programs be made to work this way? Could they be suspended and resumed mid-operation, even transplanted or copied to another machine? Imagine if instead of a screenshot, a tester could send a process snapshot that can actually be resumed and inspected by a developer. Why did it ever only 'work on my machine'?
Obviously virtual machines exist, and so does wholesale-VM debugging. But on the process level, it's generally a non-starter, because sockets and files and drivers mess it up. External resources won't be tracked while suspended and will likely end up in an invalid state on resume. VMs have well-defined boundaries and well-defined hardware to emulate, whereas operating systems are a complete wild west.
It's worth considering the worth of a paper trail here too. If I suspend a program while a socket is open, and then resume it, what does this actually mean? If it was a one-time request, like an HTTP GET or PUT, I will probably want to retry that request, if at all still relevant. Maybe I prefer to drop it as unimportant and make a newer, different request. If it was an ongoing connection like a WebSocket, I will want to re-establish it. Which is to say, if you told a network layer the reason for opening a socket, maybe it could safely abort and resume sockets for you, subject to one of several policies, and network programming could actually become pleasant.
Files can receive a similar treatment, to deal with the situation where they may have changed, been deleted, moved, etc. Knowing why a file was opened or being written to is required to do this right, and depends on the specific task being accomplished. Here too macOS deserves a shout-out, for being clever enough to realize that if a user moves a file, any application editing that file should switch to the new location as well.
Systems-level programmers tend to orchestrate such things by hand when needed, but the data flow in many cases is quite unidirectional. If a process, or a part of a process, could resume and reconnect with its resources according to prior declared intent, it would make a lot of state machines disappear.
It's not a coincidence this post started with React. Even those aware of it still don't quite realize React is not actually a thing to make web apps. It is an incremental job scheduler, for recursively expanding a tree in an asynchronous and rewindable fashion. It just happens to be built for SGML-like trees, and contains a bunch of legacy fixes for browsers. The pattern can be applied to many areas that are not UI and not web. If it sounds daunting to consider approaching resources this way, consider that people thought exactly the same about async I/O until someone made that pleasant enough.
However, doing this properly will probably require going back further than you think. For example, when you re-establish a socket, should you repeat and confirm the DNS lookup that gave you the IP in the first place? Maybe the user moved locations between suspending and resuming, so you want to reconnect to the nearest data center. Maybe there is no longer a need for the socket because the user went offline.
All of this is contextual, defined by policies informed by the real world. This class of software behavior is properly called etiquette. Like its real world counterpart it is extremely messy because it involves anticipating needs. Usually we only get it approximately right through a series of ad-hoc hacks to patch the worst annoyances. But it is eminently felt when you get such edge cases to work in a generic and reproducible fashion.
Mainly it requires treating policies as first class citizens in your designs and code. This can also lead you to perceive types in code in a different way. A common view is that a type constrains any code that refers to it. That is, types ensure your code only applies valid operations on the represented values. When types represent policies though, the perspective changes because such a type's purpose is not to constrain the code using it. Rather, it provides specific guarantees about the rules of the universe in which that code will be run.
This to me is the key to developer happiness. As opposed to, say, making tools to automate the refactoring of terrible code and make it bearable, but only just.
The key to end-user happiness is to make tools that enable an equivalent level of affordance and flexibility compared to what the developer needed while developing it.
* * *
When you look at code from a data-centric view, a lot of things start to look like stale or inconsistent data problems. I don't like using the word "cache" for this because it focuses on the negative, the absence of fresh input. The real issue is data dependencies, which are connections that must be maintained in order to present a cohesive view and cohesive behavior, derived from a changing input model. Which is still the most practical way of using a computer.
Most caching strategies, including 99% of those in HTTP, are entirely wrong. They fall into the give-up-and-pray category, where they assume the problem is intractable and don't try something that could actually work in all cases. Which, stating the obvious, is what you should actually aim for.
Often the real problem is that the architect's view of the problem is a tangled mess of boxes and arrows that point all over the place, with loopbacks and reversals, which makes it near-impossible to anticipate and cover all the applicable scenarios.
If there is one major thread running through this, it's that many currently accepted sane defaults really shouldn't be. In a world of terabyte laptops and gigabyte GPUs they look suspiciously like premature optimization. Many common assumptions deserve to be re-examined, at least if we want to adapt tools like from the Offline Age to a networked day. We really don't need a glossier version of a Microsoft Office 95 wizard with a less useful file system.
We do need optimized code in our critical paths, but developer time is worth more than CPU time most everywhere else. Most of all, we need the ambition to build complete tools and the humility to grant our users access on an equal footing, instead of hoarding the goods.
The argument against these practices is usually that they lead to bloat and inefficiency. Which is definitely true. Yet even though our industry has not adopted them much at all, the software already comes out orders of magnitude bigger and slower than before. Would it really be worse?