
Model-View-Catharsis
MVC was a mistake
Infinite omnipotent hyperbeing lovingly screaming "YOU'RE VALID", its song echoed across every structural detail of the universe—you, an insignificant mote adrift in some galactic tide shouting back "YES, OKAY, WHAT ELSE?"Fragnemt by ctrlcreep
(a linguistic anti-depressant in book form)
A reader sent in the following letter:
Dear Mr. Wittens,
I have read with great interest your recent publications in Computers Illustrated. However, while I managed to follow your general exposition, I had trouble with a few of the details.
Specifically, Googling the phrase "topping from the bottom" revealed results that I can only describe as being of an unchristian nature, and I am unable to further study the specific engineering practice you indicated. I am at a loss in how to apply this principle in my own work, where I am currently building web forms for a REST API using React. Should I have a conversation about this with my wife?
With respect,
Gilbert C.
Dear Gilbert,
In any marriage, successful copulation requires commitment and a mutual respect of boundaries. Unlike spouses however, components are generally not monogamous, and indeed, best results are obtained when they are allowed to mate freely and constantly, even with themselves. They are quite flexible.
The specifics of this style are less important than the general practice, which is about the entity ostensibly in control not actually being in control. This is something many form libraries get wrong, React or not, missing the true holy trinity. I will attempt to explain. This may take a while. Grab some hot chocolate.

That's Numberwang
In your web forms, you're building a collection of fields, and linking them to a data model. Either something to be displayed, or something to be posted, possibly both. Or even if it's a single-page app and it's all for local consumption only, doesn't really matter.
Well, it does, but that's boundary number 1. A form field shouldn't know or care about the logistics of where its data lives or what it's for. Its only task is to specialize the specific job of instantiating the value and manipulating it.
There's another boundary that we're also all used to: widget type. A text field is not a checkbox is not a multi-select. That's boundary number 3. It's the front of the VCR, the stuff that's there so that we can paw at it.
Would you like to buy a vowel for door number 2?

"Previously, on Acko."
You see, when God divided the universe into controlled (value = x) and uncontrolled (initialValue = defaultValue = x) components, He was Mistaken. A true uncontrolled component would have zero inputs.
What you actually have is a component spooning with an invisible policy. Well, if you can't pull them apart, I guess they're not just spooning. But these two are:
<ValidatingInput
parse={parseNumber} format={formatNumber}
value={number} setValue={setNumber}
>{
(value, isError, onChange, onBlur) =>
<TextField
value={value} isError={isError}
onChange={onChange} onBlur={onBlur} />
}</ValidatingInput>
This ValidatingInput ensures that a value can be edited in text form, using your parser and serializer. It provides Commitment, not Control. The C in MVC was misread in the prophecies I'm afraid. Well actually, someone spilled soda on the scrolls, and the result was a series of schisms over what they actually said. Including one ill-fated attempt to replace the Controller with a crazy person.
Point is, as long as the contents of the textfield are parseable, the value is plumbed through to the outside. When it's not, only the text inside the field changes, the inner value. The outside value doesn't, remaining safe from NaNful temptations. But the TextField remains in control, only moderated by the two policies you passed in. The user is free to type in unparseable nonsense while attempting to produce a valid value, rather than having their input messed around with as they type. How does it know it's invalid? If the parser throws an Error. A rare case of exceptions being a good fit, even if it's the one trick VM developers hate.
An "uncontrolled component" as React calls it has a policy to never write back any changes, requiring you to fish them out manually. Its setValue={} prop is bolted shut.
Note our perspective as third party: while we cannot see or touch ValidatingInput's inner workings, it still lets us have complete control over how it actually gets used, both inside and out. You wire it up to an actual widget yourself, and direct its behavior completely. It's definitely not a controller.
This is also why, if you pass in JSON.parse and JSON.stringify as the parser/formatter, with the pretty printer turned on, you get a basic but functional JSON editor for free.
You can also have a DirectInput, to edit text directly in its raw form, without any validation or parsing. Because you wrote that one first, to handle the truly trivial case. But then later you realized it was just ValidatingInput with identity functions glued into the parse/format props.
So let's talk about MVC and see how much is left once you realize the above looks suspiciously like a better, simpler recipe for orthogonalized UI.

Look at this. It's from Wikipedia so it must be true. No really, look at it closely. There is a View, which only knows how to tell you something. There is a Controller, which only knows how to manipulate something.
This is a crack team of a quadriplegic and a blind man, each in separate rooms, and you have to delegate your UI to them? How, in the name of all that is holy, are you supposed to do that? Prisoner dilemmas and trolleys? No really, if the View is a TextField, with a keyboard cursor, and mouse selection, and scrolling, and Japanese, how is it possible to edit the model backing it unless you are privy to all that same information? What if it's a map or a spreadsheet? ばか!
This implies either one of two things. First, that the Controller has to be specialized for the target widget. It's a TextController, with its own house key to the TextView, not pictured. Or second, that the Controller doesn't do anything useful at all, it's the View that's doing all the heavy lifting, the Controller is just a fancy setter. The TextModel certainly isn't supposed to contain anything View-specific, or it wouldn't be MVC.
Wikipedia does helpfully tell us that "Particular MVC architectures can vary significantly from the traditional description here." but I would argue the description is complete and utter nonsense. Image-googling MVC is however a fun exercise for all the zany diagrams you get back. It's a puzzle to figure out if any two actually describe the same thing.
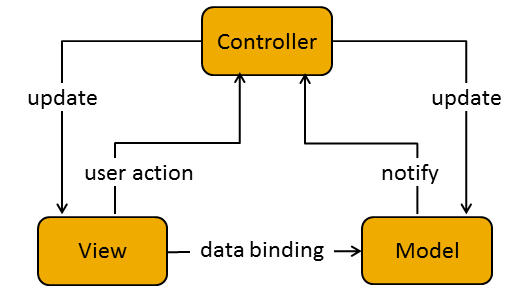
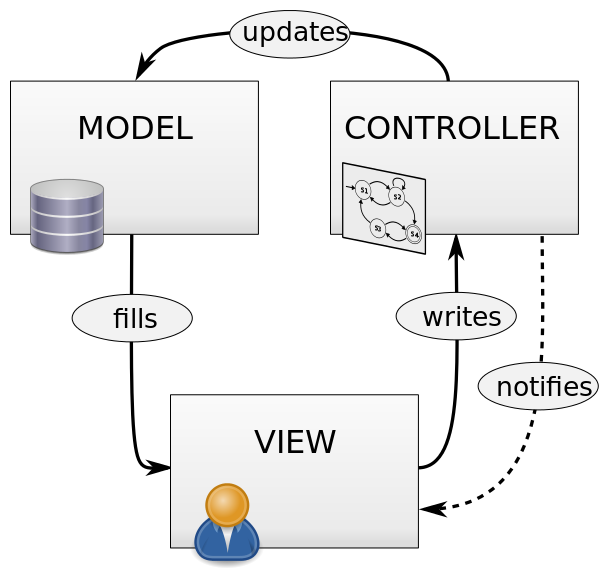
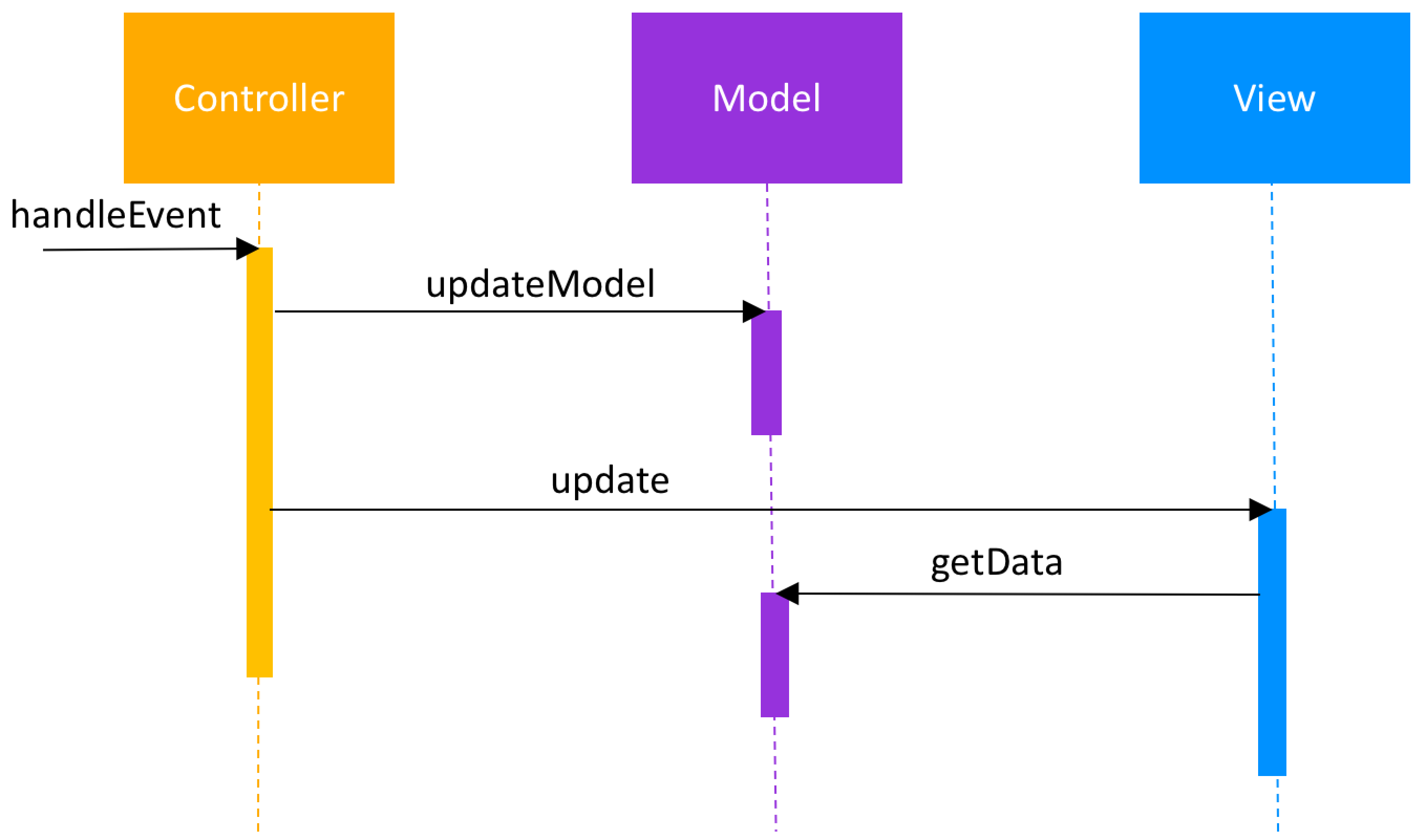
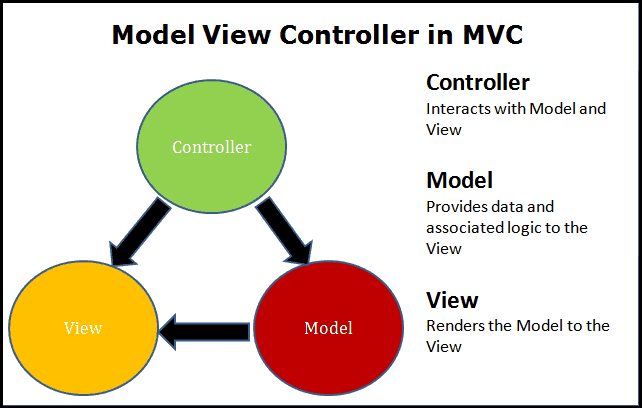
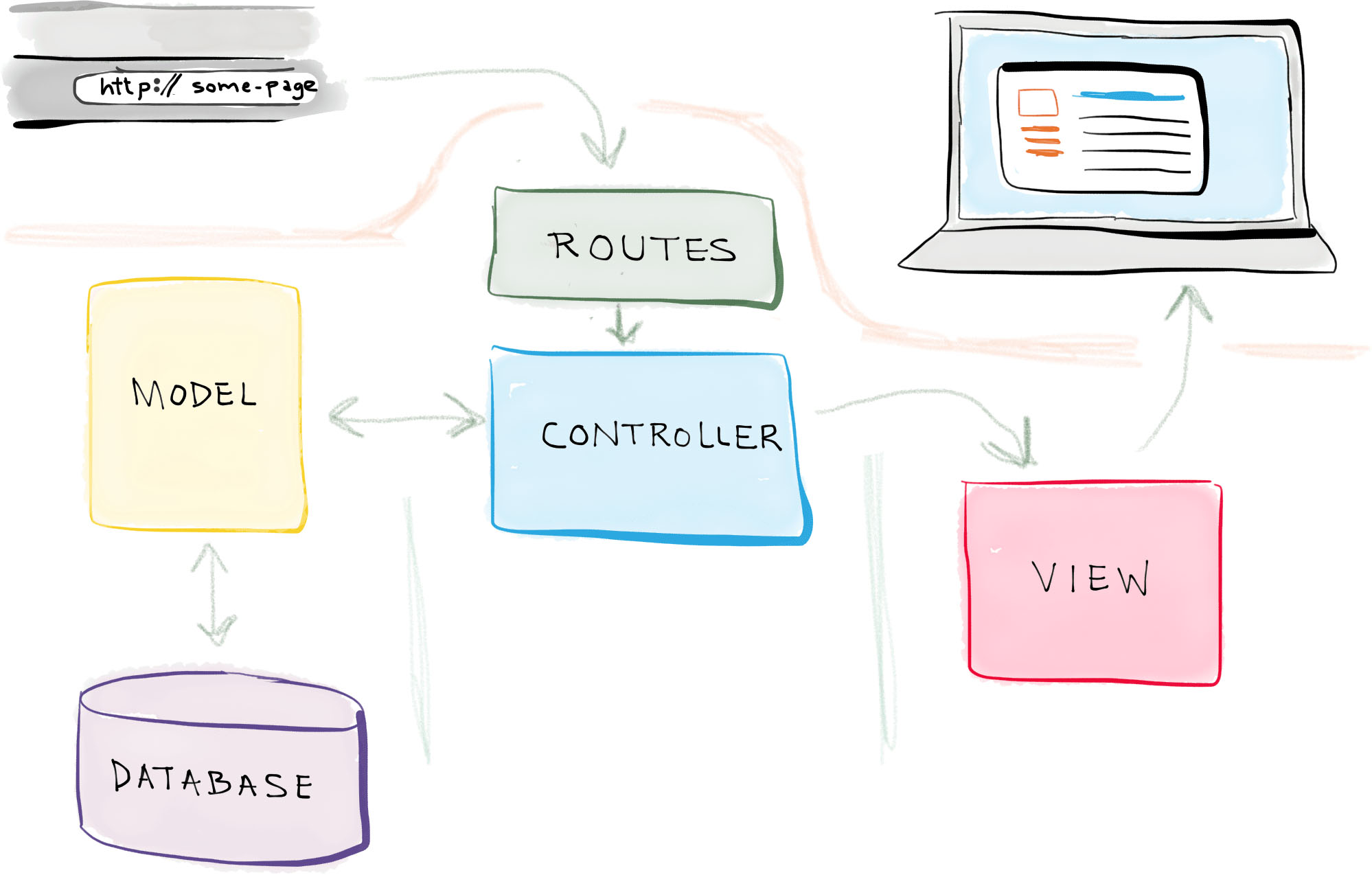
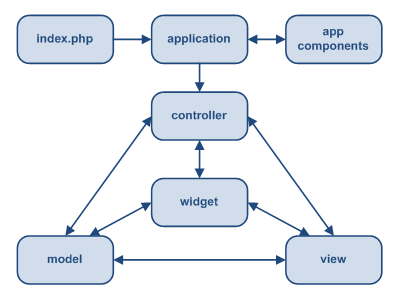
Nobody can agree on who talks to who, in what order, and who's in charge. For some, the Controller is the one who oversees the entire affair and talks to the user, maybe even creates the Model and View. For others, it's the View that talks to the user, possibly creating a Controller and fetching a Model. For some, the Model is just a data structure, mutable or immutable. For others it's an interactive service to both Controller and View. There may be an implicit 4th observer or dispatcher for each trio. What everyone does agree on, at least, is that the program does things, and those things go in boxes that have either an M, a V or a C stamped on them.
One dimension almost never illustrated, but the most important one, is the scope of the MVC in question.

Sometimes MVC is applied at the individual widget level, indeed creating a TextModel and a TextView and a TextController, which sits inside a FormModel/View/Controller, nested inside an ActivityModel/View/Controller. This widget-MVC approach leads to a massively complected tree, where everything comes in triplicate.
The models each contain partial fragments of an original source repeated. Changes are sometimes synced back manually, easily leading to bugs. Sometimes they are bound for you, but must still travel from a deeply nested child all the way back through its parents. If a View can't simply modify its Model without explicitly tripping a bunch of other unrelated Model/Controller/View combos, to and fro, this is probably an architectural mistake. It's a built-in game of telephone played by robots.
I didn't try to draw all this, because then I'd also have to define which of the three has custody of the children, which is a very good question.

But sometimes people mean the exact opposite, like client/server MVC. There the Model is a whole database, the Controller is your web application server and the View is a templated client-side app. Maybe your REST API is made up of orthogonal Controllers, and your Models are just the rows in the tables pushed through an ORM, with bells on and the naughty bits censored. While this explanation ostensibly fits, it's not accurate. A basic requirement for MVC is that the View always represents the current state of the Model, even when there are multiple parallel Views of the same thing. REST APIs simply don't do that, their views are not live. Sorry Rails.
It is in fact this last job that is difficult to do right, and which is the problem we should not lose sight of. As ValidatingInput shows, there is definitely a requirement to have some duplication of models (text value vs normalized value). Widgets definitely need to retain some local state and handlers to manage themselves (a controller I guess). But it was never about the boxes, it was always about the arrows. How can we fix the arrows?
(An audience member built like a greek statue stands up and shouts: "Kleisli!" A klaxon sounds and Stephen Fry explains why that's not the right answer.)
The Shape of Things To Come
In my experience, the key to making MVC work well is to focus on one thing only: decoupling the shape of the UI from the shape of the data. I don't just mean templating. Because if there's one thing that's clear in modern apps, it's that widgets want to be free. They can live in overlays, side drawers, pop-overs and accordions. There is a clear trend towards canvas-like apps, most commonly seen with maps, where the main artifact fills the entire screen. The controls are entirely contextual and overlaid, blocking only minimal space. Widgets also move and transition between containers, like the search field in the corner, which jumps between the map and the collapsible sidebar. The design is and should be user-first. Whether data is local or remote, or belongs to this or that object, is rarely a meaningful distinction for how you display and interact with it.

So you don't want to structure your data like your UI, that would be terrible. It would mean every time you want to move a widget from one panel to another, you have to change your entire data model end-to-end. Btw, if an engineer is unusually resistant to a proposed UI change, this may be why. Oops. But what shape should it have then?
You should structure your data so that GETs/PUTs that follow alike rules can be realized with the same machinery through the same interface. Your policies aren't going to change much, at least not as much as your minimum viable UI. This is the true meaning of full stack, of impedance matching between front-end and back-end. You want to minimize the gap, not build giant Stålenhag transformers on both sides.
Just because structuring your data by UI is bad, doesn't mean every object should be flat. Consider a user object. What structure would reflect the various ways in which information is accessed and modified? Maybe this:
user {
id,
avatar,
email,
profile {
name, location, birthday
},
// ...
}
There is a nice profile wrapper around the parts a user can edit freely themselves. Those could go into a separately grafted profile table, or not. You have to deal with file uploads and email changes separately anyway, as special cases. Editing a user as a whole is out of the question for non-admins. But when only the profile can be edited, there's no risk of improper change of an email address or URL, and that's simpler to enforce when there's separation. Also remember the password hash example, because you never give it out, and it's silly to remove it every time you fetch a user. Proper separation of your domain models will save you a lot of busywork later, of not having to check the same thing in a dozen different places. There's no one Right Way to do it, rather, this is about cause and effect of your own choices down the line, whatever they are.
There's also an entirely different split to respect. Usually in additional to your domain models, you also have some local state that is never persisted, like UI focus, active tab, playback state, pending edits, ... Some of this information is coupled to domain models, like your users, which makes it tempting to put it all on the same objects. But you should never cross the streams, because they route to different places. Again, the same motivation of not having to strip out parts of your data before you can use it for its intended purpose. You can always merge later.
You can also have an in-between bucket of locally persisted state, e.g. to rescue data and state from an accidentally closed tab. Figuring out how it interacts with the other two requires some thought, but with the boundary in the right place, it's actually feasible to solve it right. Also important to point out: you don't need to have only one global bucket of each type. You can have many.
So if you want to do MVC properly, you should separate your models accordingly and decouple them from the shape of the UI. It's all about letting the data pave the cow paths of the specific domain as naturally as possible. This allows you to manipulate it as uniformly as possible too. You want your Controller to be just a fancy getter/setter, only mediating between Model and View, along the boundaries that exist in the data and not the UI. Don't try to separate reading and writing, that's completely counterproductive. Separate the read-only things from the read-write things.
A mediating Controller is sometimes called a ViewModel in the Model-View-ViewModel model, or more sanely Model-View-Presenter, but the name doesn't matter. The difficult part in the end is still the state transitions on the inside, like when ValidatingInput forcefully reformats the user's text vs when it doesn't. That's what the onBlur was for, if you missed it. In fact, if the View should always reflect the Model, should an outside change overwrite an internal error state? What if it's a multi-user environment? What if you didn't unfocus the textfield before leaving your desk? Falsehoods programmers believe about interaction. Maybe simultaneous props and derived state changes are just unavoidably necessary for properly resolving UI etiquette.
I have another subtle but important tweak. React prefab widgets like TextField usually pass around DOM events. Their onChange and onBlur calls carry a whole Event, but 99% of the time you're just reading out the e.target.value. I imagine the reasoning is that you will want to use the full power of DOM to reach into whatever library you're using and perform sophisticated tricks on top of their widgets by hand. No offense, but they are nuts. Get rid of it, make a TextField that grabs the value from its own events and calls onChange(value) directly. Never write another trivial onChange handler just to unbox an event again.
This:
<TextField ...
onChange={e => setValue(e.target.value)} />could be:
<TextField ...
onChange={setValue} />If you do need to perform the rare dark magic of simultaneous hand-to-hand combat against every platform and browser's unique native textfield implementation (i.e. progressive enhancement of <input />), please do it yourself and box in the component (or hook) to keep it away from others. Don't try to layer it on top of an existing enhanced widget in a library, or allow others to do the same, it will be a nightmare. Usually it's better to just copy/paste what you can salvage and make a new one, which can safely be all fucky on the inside. Repetition is better than the wrong abstraction, and so is sanity.
Really, have you ever tried to exactly replicate the keyboard/mouse behavior of, say, an Excel table in React-DOM, down to the little details? It's an "interesting" exercise, one which shows just how poorly conceived some of HTML's interactivity truly is. React was victorious over the DOM, but its battle scars are still there. They should be treated and allowed to fade, not wrapped in Synthetic and passed around like precious jewels of old.
Synthesis
What you also shouldn't do is create a special data structure for scaffolding out forms, like this:
[
{
type: "textfield",
label: "Length"
format: {
type: "number",
precision: 2,
units: "Meters",
},
},
{
// ...
},
// ...
]
(If your form arrays are further nested and bloated, you may have a case of the Drupals and you need to have that looked at, and possibly, penicillin).
You already have a structure like that, it's your React component tree, and that one is incremental, while this one is not. It's also inside out, with the policy as the little spoon. This may seem arbitrary, but it's not.
Now might be a good time to explain that we are in fact undergoing the Hegelian synthesis of Immediate and Retained mode. Don't worry, you already know the second half. This also has a better ending than Mass Effect, because the relays you're going to blow up are no longer necessary.
Immediate Mode is UI coding you have likely never encountered before. It's where you use functions to make widgets (or other things) happen immediately, just by calling them. No objects are retained per widget. This clearly can't work, because how can there be interactivity without some sort of feedback loop? It sounds like the only thing it can make is a dead UI, a read-only mockup. Like this dear-imgui code in Rust:
ui.with_style_var(StyleVar::WindowPadding((0.0, 0.0).into()), || {
ui.window(im_str!("Offscreen Render"))
.size((512.0 + 10.0, 512.0 + 40.0), ImGuiCond::Always)
.scrollable(false)
.scroll_bar(false)
.build(|| {
ui.columns(2, im_str!(""), false);
for i in 0..4 {
ui.image(self.offscreen_textures[i], (256.0, 256.0))
.build();
ui.next_column();
}
})
});

We draw a window, using methods on the ui object, with some ui.image()s inside, in two columns. There are some additional properties set via methods, like the initial size and no scrollbars. The inside of the window is defined using .build(...) with a closure that is evaluated immediately, containing similar draw commands. Unlike React, there is no magic, nothing up our sleeve, this is plain Rust code. Clearly nothing can change, this code runs blind.
But actually, this is a fully interactive, draggable window showing a grid of live image tiles. It'll even remember its position and open/collapsed state across program restarts out of the box. You see, when ui.window is called, its bounding box is determined so that it can be drawn. This same information is then immediately used to see if the mouse cursor is pointing at it and where. If the left button is also down, and you're pointing at the title bar, then you're in the middle of a drag gesture, so we should move the window by whatever the current motion is. This all happens in the code above. If you call it every frame, with correct input to ui, you get a live UI.
So where does the mouse state live? At the top, inside ui. Because you're only ever interacting with one widget at a time, you don't actually need a separate isActive state on every single widget, and no onMouseDown either. You only need a single, global activeWidget of type ID, and a single mouseButtons. At least without multi-touch. If a widget discovers a gesture is happening inside it, and no other widget is active, it makes itself the active one, until you're done. The global state tracks mouse focus, button state, key presses, the works, in one data structure. Widget IDs are generally derived from their position in the stack, in relation to their parent functions.
Every time the UI is re-rendered, any interaction since the last time is immediately interpreted and applied. With some imagination, you can make all the usual widgets work this way. You just have to think a bit differently about the problem, sharing state responsibly with every other actor in the entire UI. If a widget needs to edit a user-supplied value, there's also "data binding," in the form of passing a raw memory pointer, rather than the value directly. The widget can read/write the value any way it likes, without having to know who owns it and where it came from.

Immediate mode UI is so convenient and efficient because it reuses the raw building blocks of code as its invisible form structure: compiled instructions, the stack, pointers, nested function calls, and closures. The effect is that your UI becomes like Deepak Chopra explaining quantum physics, it does not exist unless you want to look at it, which is the same as running it. I realize this may sound like moon language, but there is a whole lecture explaining it if you'd like to know more. Plus 2005 Casey Muratori was dreamboat.
The actual output of dear-imgui, not visible in this code at all, is raw geometry, produced from scratch every frame and passed out through the back. It's pure unretained data. This is pure vector graphics, directly sampled. It can be rendered using a single GPU shader with a single image for the font. All the shapes are triangle meshes with RGBA colors at their vertices, including the anti-aliasing, which is a 1px wide gradient edge.
Its polar opposite is Retained mode, what you likely have always used, where you instead materialize a complete view tree. Every widget, label and shape is placed and annotated with individual styling and layout. You don't recompute this tree every frame, you only graft and prune it, calling .add(...) and .set(...) and .remove(...). It would seem more efficient and frugal, but in fact you pay for it tenfold in development overhead.
By materializing a mutable tree, you have made it so that now the evolution of your tree state must be done in a fully differential fashion, not just computed in batch. Every change must be expressed in terms of how you get there from a previous state. Given n states, there are potentially O(n2) valid pairwise transitions. Coding them all by hand, for all your individual Ms, Vs and Cs, however they work, is both tedious and error-prone. This is called Object-Oriented Programming.
What you generally want to do instead is evolve your source of truth differentially, and to produce the derived artifact—the UI tree—declaratively. IM UI achieves this, because every function call acts as a declarative statement of the desired result, not a description of how to change the previous state to another. The cost is that your UI is much more tightly coupled with itself, and difficult to extend.

The React model bridges the two modes. On the one hand, its render model provides the same basic experience as immediate UI, except with async effects and state allocation integrated, allowing for true decoupling. But it does this by automating the tedium, not eliminating it, and still materializes an entire DOM tree in the end, whose changes the browser then has to track itself anyway.
I never said it was a good Hegelian synthesis.
If you've ever tried to interface React with something that isn't reactive, like Three.js, you know how silly it feels to hook up the automatic React lifecycle to whatever manual native add/set/remove methods exist. You're just making a crummier version of React inside itself, lacking the proper boundaries and separation.

But we can make it right. We don't actually need to produce the full manifest and blueprint down to every little nut and bolt, we just need to have a clear enough project plan of what we want. What if the target library was immediate instead of retained, or as close as can be and still be performant, and the only thing you kept materialized inside React was the orchestration of the instructions? That is, instead of materializing a DOM, you materialize an immediate mode program at run-time. This way, you don't need to hard-wrap what's at the back, you can plumb the same interface through to the front.
We don't need to expand React functions to things that aren't functions, we just need to let them stop expanding, into a function in which an immediate mode API is called directly. The semantics of when this function is called will need to be clearly defined with suitable policies, but they exist to empower you, not to limit you. I call this Deferred Mode Rendering (nothing like deferred shading). It may be a solution to the lasagna from hell in which Retained and Immediate mode are stacked on top of each other recursively, each layer more expired than the next.
What this alternate <Component /> tree expands into, in the React model, is placeholder <div />s with render props. The deferred mode layers could still bunch up at the front, but they wouldn't need to fence anything off, they could continue to expose it. Because the context => draw(context) closures you expand to can be assembled from smaller ones, injected into the tree as props by parents towards their children. Somewhat like an algebraically closed reducer.
To do this today requires you to get familiar with the React reconciler and its API, which is sadly underdocumented and a somewhat shaky house of cards. There is a mitigating factor though, just a small one, namely that the entirety of React-DOM and React-Native depend on it. For interactivity you can usually wing it, until you hit the point where you need to take ownership of the event dispatcher. But on the plus side, imagine what your universe would be like if you weren't limited by the irreversible mistakes of the past, like not having to have a 1-to-1 tight coupling between things that are drawn and things that can be interacted with. This need not mean starting from scratch. You can start to explore these questions inside little sandboxes you carve out entirely for yourself, using your existing tools inside your existing environment.
If you'd rather wait for the greybeards to get their act together, there is something else you can do. You can stop breaking your tools with your tools and start fixing them.
The Stateless State
I glossed over boundary 1, where the data comes from and where it goes, but in fact, this is where the real fun stuff happens, which is why I had to save it for last.
The way most apps will do this, is to fetch data from a RESTlike API. This is stored in local component state, or if they're really being fancy, a client-side document store organized by URL or document ID. When mutations need to be made, usually the object in question is rendered into a form, then parsed on submit back into a POST or PUT request. All of this likely orchestrated separately for every mutation, with two separate calls to fetch() each.
If you use the API you already have:
let [state, setState] = useState(initialValue);
Then as we've seen, this useState allocates persistent data that can nevertheless vanish at any time, as can we. That's not good for remote data. But this one would be:
// GET/PUT to REST API
let [state, setState] = useRESTState(cachedValue, url);
It starts from a cached value, if any, fetches the latest version from a URL, and PUTs the result back if you change it.
Now, I know what you're thinking, surely we don't want to synchronize every single keystroke with a server, right? Surely we must wait until an entire form has been filled out with 100% valid content, before it may be saved? After all, MS Word prevented you from saving your homework at all unless you were completely done and had fixed all the typos, right? No wait, several people are typing, and no. Luckily it's not an either/or thing. It's perfectly possible to create a policy boundary between what should be saved elsewhere on submission and what should be manipulated locally:
<Form state={state} setState={setState} validate={validate}>{
(state, isError, onSubmit) => {
// ...
}
}</Form>
It may surprise you that this is just our previous component in drag:
<ValidatingInput value={state} setValue={setState} validate={validate}>{
(state, isError, onSubmit) => {
// ...
}
}</ValidatingInput>
If this doesn't make any sense, remember that it's the widget on the inside that decides when to call the policy's onChange handler. You could wire it up to a Submit button's onClick event instead. Though I'll admit you probably want a Form specialized for this role, with a few extra conveniences for readability's sake. But it would just be a different flavor of the same thing. Notice if onSubmit/onChange takes an Event instead of a direct value it totally ruins it, q.e.d.
In fact, if you want to only update a value when the user unfocuses a field, you could hook up the TextField's onBlur to the policy's onChange, and use it in "uncontrolled" mode, but you probably want to make a BufferedInput instead. Repetition better than the wrong abstraction strikes again.
You might also find these useful, although the second is definitely an extended summer holiday assignment.
// Store in window.localStorage
let [state, setState] = useLocalState(initialValue, url);
// Sync to a magical websocket API
let [state, setState] = useLiveState(initialValue, url);
But wait, there's something missing. If these useState() variants apply at the whole document level, how do you get setters for your individual form fields? What goes between the outer <Shunt /> and the inner <Shunt />?
Well, some cabling:
let [state, setState] = useState({
metrics: {
length: 2,
mass: 10,
},
// ...
});
let useCursor = useRefineState(state, setState);
let [length, setLength] = useCursor('metrics', 'length');
let [mass, setMass] = useCursor('metrics', 'mass');
What useCursor does is produce an automatic reducer that will overwrite e.g. the state.metrics.length field immutably when you call setLength. A cursor is basically just a specialized read/write pointer. But it's still bound to the root of what it points to and can modify it immutably, even if it's buried inside something else. In React it makes sense to use [value, setter] tuples. That is to say, you don't play a new game of telephone with robots, you just ask the robots to pass you the phone. With a PBX so you only ever dial local numbers.
Full marks are awarded only when complete memoization of the refined setter is achieved. Because you want to pass it directly to some policy+input combo, or a more complex widget, as an immutable prop value on a memoized component.
A Beautiful Bikeshed
Having now thrown all my cards on the table, I imagine the urge to nitpick or outright reject it has reached critical levels for some. Let's play ball.
I'm aware that the presence of string keys for useCursor lookups is an issue, especially for type safety. You are welcome to try and replace them with a compile-time macro that generates the reader and writer for you. The point is to write the lookup only once, in whatever form, instead of separately when you first read and later write. Possibly JS proxies could help out, but really, this is all trying to paper over language defects anyway.
Unlike most Model-View-Catastrophes, the state you manage is all kept at the top, separating the shape of the data from the shape of the UI completely. The 'routes' are only defined in a single place. Unlike Redux, you also don't need to learn a whole new saga, you just need to make your own better versions of the tools you already have. You don't need to centralize religiously. In fact, you will likely want to use both useRESTState and useLocalState in the same component sooner than later, for data and UI state respectively. It's a natural fit. You will want to fetch the remote state at the point in the tree where it makes the most sense, which is likely near but not at its root. This is something Apollo does get right.
In fact, now replace useState(...) with [state, updateState] = useUpdateState(...), which implements a sparse update language, using a built-in universal reducer, and merges it into a root state automatically. If you want to stream your updates as OT/CRDT, this is your chance to make a useCRDTState. Or maybe you just want to pass sparse lambda updates directly to your reducer, because you don't have a client/server gap to worry about, which means you're allowed to do:
updateState({foo: {thing: {$apply: old => new}}})
Though that last update should probably be written as:
let [thing, updateThing] = useCursor('foo', 'thing');
// ...
updateThing($apply(old => new));
useCursor() actually becomes simpler, because now its only real job is to turn a path like ['foo', 'bar'] into the function:
value => ({foo: {bar: value}})...with all the reduction logic part of the original useUpdateState().
Of course, now it's starting to look like you should be able to pass a customized useState to any other hook that calls useState, so you can reuse it with different backing stores, creating higher-order state hooks:
let useRemoteState = useRESTState(url);
let useRemoteUpdatedState = useUpdateState(initialValue, useRemoteState);
Worth exploring, for sure. Maybe undo/redo and time travel debugging suddenly became simpler as well.
Moving on, the whole reason you had centralized Redux reducers was because you didn't want to put the update logic inside each individual component. I'm telling you to do just that. Yes but this is easily fixed:
updateThing(manipulateThing(thing, ...));
manipulateThing returns an update representing the specific change you requested, in some update schema or language, which updateThing can apply without understanding the semantics of the update. Only the direct effects. You can also build a manipulator with multiple specialized methods if you need more than one kind of update:
updateSelection(
manipulateSelection(selection)
.toggleOne(clicked)
);
Instead of dispatching bespoke actions just so you can interpret them on the other side, why not refactor your manipulations into reusable pieces that take and return modified data structures or diffs thereof. Use code as your parts, just like dear-imgui. You compute updates on the spot that pass only the difference on, letting the cursor's setter map it into the root state, and the automatic reducer handle the merge.
In fact, while you could conscientiously implement every single state change as a minimal delta, you don't have to. That is, if you want to reorder some elements in a list, you don't have to frugally encode that as e.g. a $reorder operation which maps old and new array indices. You could have a $splice operation to express it as individual insertions and removals. Or if you don't care at all, the bulkiest encoding would be to replace the entire list with $set.
But if your data is immutable, you can efficiently use element-wise diffing to automatically compress any $set operation into a more minimal list of $splices, or other more generic $ops or $nops. This provides a way to add specialized live sync without having to rewrite every single data structure and state change in your app.
If diffing feels icky, consider that the primary tool you use for development, git, relies on it completely to understand everything you get paid for. If it works there, it can work here. For completeness I should also mention immer, but it lacks cursor-like constructs and does not let you prepare updates without acting on them right away. However, immer.produce could probably be orthogonalized as well.
Maybe you're thinking that the whole reason you had Sagas was because you didn't want to put async logic inside your UI. I hear you.
This is a tougher one. Hopefully it should be clear by now that putting things inside React often has more benefits than not doing so, even if that code is not strictly part of any View. You can offload practically all your bookkeeping to React via incremental evaluation mechanisms. But we have to be honest and acknowledge it does not always belong there. You shouldn't be making REST calls in your UI, you should be asking your Store to give you a Model. But doing this properly requires a reactive approach, so what you probably want is a headless React to build your store with.
Until that exists, you will have to accept some misappropriation of resources, because the trade-off is worth it more often than not. Particularly because you can still refactor it so that at least your store comes in reactive and non-reactive variants, which share significant chunks of code between them. The final form this takes depends on the specific requirements, but I think it would look a lot like a reactive PouchDB tbh, with the JSON swapped out for something else if needed. (Edit: oh, and graph knitting)
To wrap it all up with a bow: one final trick, stupid, but you'll thank me. Often, every field needs a unique <label> with a unique id for accessibility reasons. Or so people think. Actually, you may not know that the entire time, you have been able to wrap the <label> around your <input> without naming either. Because <label> is an interaction policy, not a widget.
<label for="name">Name</label>
<input name="name" type="text" value="" />
Works the same as:
<label>
Name
<input type="text" value="" />
</label>
You haven't needed the name attribute (or id) on form fields for a long time now in your SPAs. But if your dependencies still need one, how about you make this work:
let [mass, setMass] = useCursor('metrics', 'mass');
// The setter has a name
// setMass.name == 'state-0-metrics-mass'
<ValidatingInput
parse={parseNumber} format={formatNumber}
value={mass} setValue={setMass}
>{
// The name is extracted for you
(name, value, isError, onChange, onBlur) =>
<TextField
name={name} value={value} isError={isError}
onChange={onChange} onBlur={onBlur} />
}</ValidatingInput>
The setter is the part that is bound to the root. If you need a name for that relationship, that's where you can put it.
As an aside "<label> is an interaction policy" is also a hint on how to orthogonalize interactions in a post-HTML universe, but that's a whole 'nother post.
When you've done all this, you can wire up "any" data model to "any" form, while all the logistics are pro forma, but nevertheless immediate, across numerous components.
You define some state by its persistence mechanism. You refine the state into granular values and their associated setters, i.e. cursor tuples. You can pass them to other components, and let change policy wrappers adopt those cursors, separately from the prefab widgets they wrap. You put the events away where you don't have to think about it. Once the reusable pieces are in place, you only write what is actually unique about this. Your hooks and your components declare intent, not change. Actual coding of differential state transitions is limited only to opportunities where this has a real pay off.
It's particularly neat once you realize that cursors don't have to be literal object property lookups: you can also make cursor helpers for e.g. finding an object in some structured collection based on a dynamic path. This can be used e.g. to make a declarative hierarchical editor, where you want to isolate a specific node and its children for closer inspection, like Adobe Illustrator. Maybe make a hook for a dynamically resolved cursor lookup. This is the actual new hotness: the nails you smashed with your <Component /> hammer are now hooks to hang declarative code off of.
Just keep in mind the price you pay for full memoization, probably indefinitely, is that all your hooks must be executed unconditionally. If you want to apply useCursor to a data.list.map() loop, that won't work. But you don't need to invent anything new, think about it. A dynamically invoked hook is simply a hook inside a dynamically rendered component. Your rows might want to individually update live anyway, it's probably the right place to put an incremental boundary.
I'm not saying the above is the holy grail, far from it, what I am saying is that it's unquestionably both simpler and easier, today, for these sorts of problems. And I've tried a few things. It gets out of the way to let me focus on building whatever I want to build in the first place, empowering my code rather than imprisoning it in tedious bureaucracy, especially if there's a client/server gap. It means I actually have a shot at making a real big boy web app, where all the decades-old conveniences work and the latency is what it should be.
It makes a ton more sense than any explanation of MVC I've ever heard, even the ones whose implementation matches their claims. The closest you can describe it in the traditional lingo is Model-Commitments-View, because the controllers don't control. They are policy components mediating the interaction, nested by scope, according to rules you define. The hyphens are cursors, a crucial part usually overlooked, rarely done right.
Good luck,
Steven Wittens
Previous: The Incremental Machine