
Headless React

- Part 1: Climbing Mount Effect - Declarative Code and Effects
- Part 2: Reconcile All The Things - Memoization, Data Flow and reconciliation
- Part 3: Headless React - Live, Yeet Reduce, No-API, WebGPU
Live
It is actually pretty easy to build a mediocre headless React today, i.e. an implementation of React that isn't hooked directly into anything else.
react-reconciler is an official package that lets you hook up React to anything already. That's how both React-DOM and React-Native share a run-time.
Most third-party libraries that use it (like react-three-fiber) follow the same approach. They are basically fully wrapped affairs: each notable Three.js object (mesh, geometry, material, light, ...) will tend to have a matching node in the React tree. Three.js has its own scene tree, like the browser has a DOM, so react-reconciler will sync up the two trees one-to-one.
The libraries need to do this, because the target is a retained in-memory model. It must be mutated in-place, and then re-drawn. But what would it look like to target an imperative API directly, like say 2D Canvas?
You can't just call an imperative API directly in a React component, because the idea of React is to enable minimal updates. There is no guarantee every component that uses your imperative API will actually be re-run as part of an update. So you still need a light-weight reconciler.
Implementing your own back-end to the reconciler is a bit of work, but entirely doable. You build a simple JS DOM, and hook React into that. It doesn't even need to support any of the fancy React features, or legacy web cruft: you can stub it out with no-ops. Then you can make up any <native /> tags you like, with any JS value as a property, and have React reconcile them.
Then if you want to turn something imperative into something declarative, you can render elements with an ordinary render prop like this:
<element render={(context) => {
context.fillStyle = "blue";
context.drawRect(/*...*/);
}} />
This code doesn't run immediately, it just captures all the necessary information from the surrounding scope, allowing somebody else to call it. The reconciler will gather these multiple "native" elements into a shallow tree. They can then be traversed and run, to form a little ad-hoc program. In other words, it's an Effect-like model again, just with all the effects neatly arranged and reconciled ahead of time. Compared to a traditional retained library, it's a lot more lightweight. It can re-paint without having to re-render any Components in React.
You can also add synthetic events like in React-DOM. These can be forwarded with conveniences like event.stopPropagation() replicated.
I've used this with great success before. Unfortunately I can't show the results here—maybe in the future—but I do have something else that should demonstrate the same value proposition.
React works hard to synchronize its own tree with a DOM-like tree, but it's just a subset of the tree it already has. If you remove that second tree, what's left? Does that one tree still do something useful by itself?
I wagered that it would and built a version of it. It's pretty much just a straight up re-implementation of React's core pattern, from the ground up. It has some minor tweaks and a lot of omissions, but all the basics of hook-driven React are there. More importantly, it has one extra superpower: it's designed to let you easily collect lambdas. It's still an experiment, but the parts that are there seem to work fine already. It also has tests.
Yeet Reduce
As we saw, a reconciler derives all its interesting properties from its one-way data flow. It makes it so that the tree of mounted components is also the full data dependency graph.
So it seems like a supremely bad idea to break it by introducing arbitrary flow the other way. Nevertheless, it seems clear that we have two very interesting flavors just asking to be combined: expanding a tree downstream to produce nodes in a resumable way, and yielding values back upstream in order to aggregate them.
Previously I observed that trying to use a lambda in a live DFG is equivalent to potentially creating new outputs out of thin air. Changing part of a graph means it may end up having different outputs than before. The trick is then to put the data sinks higher up in the tree, instead of at the leaves. This can be done by overlaying a memoized map-reducer which is only allowed to pass things back in a stateless way.
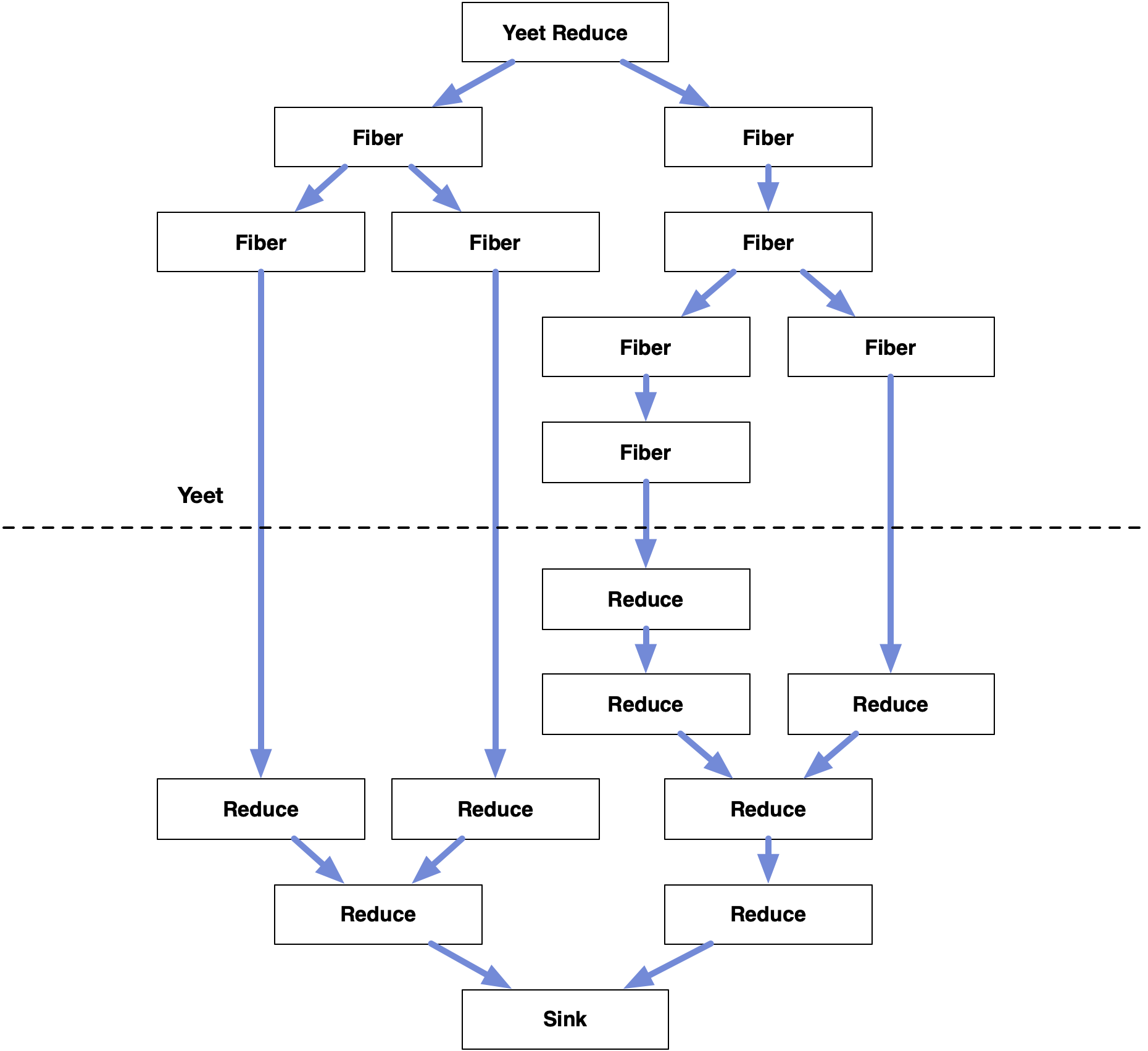
The resulting data flow graph is not in fact a two-way tree, which would be a no-no: it would have a cycle between every parent and child. Instead it is a DFG consisting of two independent copies of the same tree, one forwards, one backwards, glued together. Though in reality, the second half is incomplete, as it only needs to include edges and nodes leading back to a reducer.
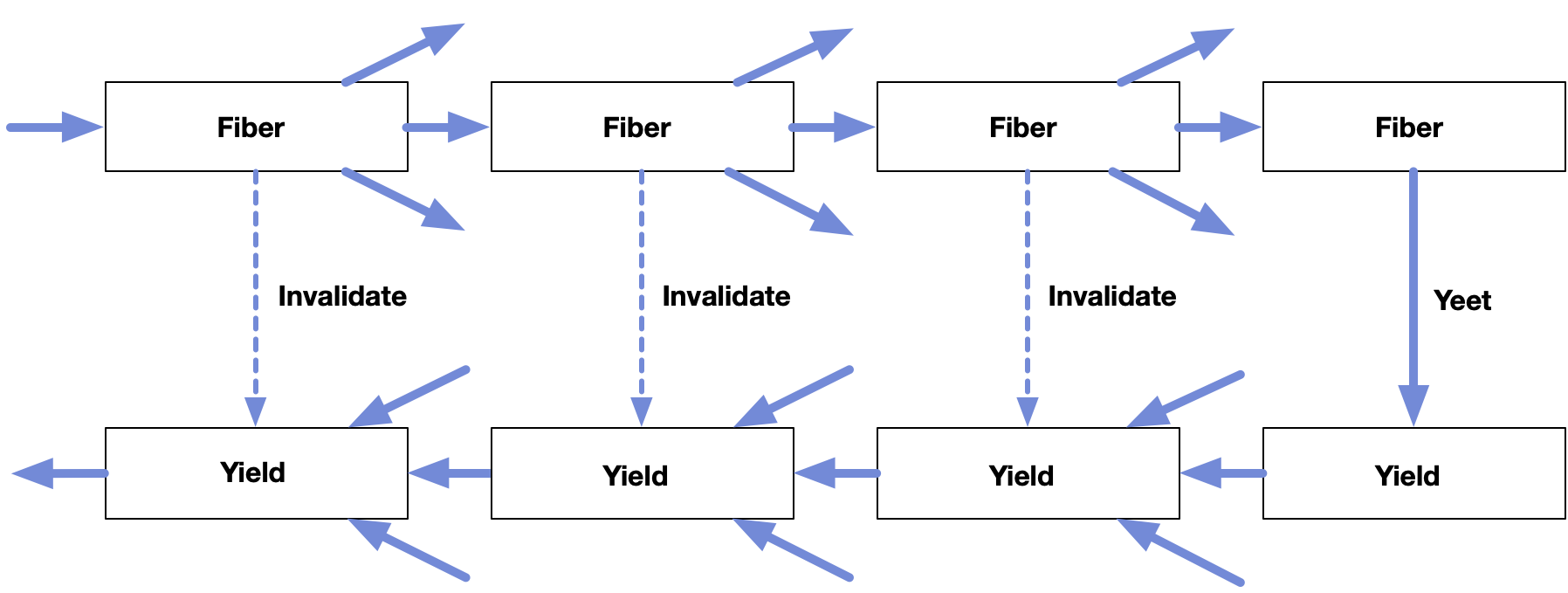
Thus we can memoize both the normal forward pass of generating nodes and their sinks, as well as the reverse pass of yielding values back to them. It's two passes of DFG, one expanding, one contracting. It amplifies input in the first half by generating more and more nodes. But it will simultaneously install reducers as the second half to gather and compress it back into a collection or a summary.
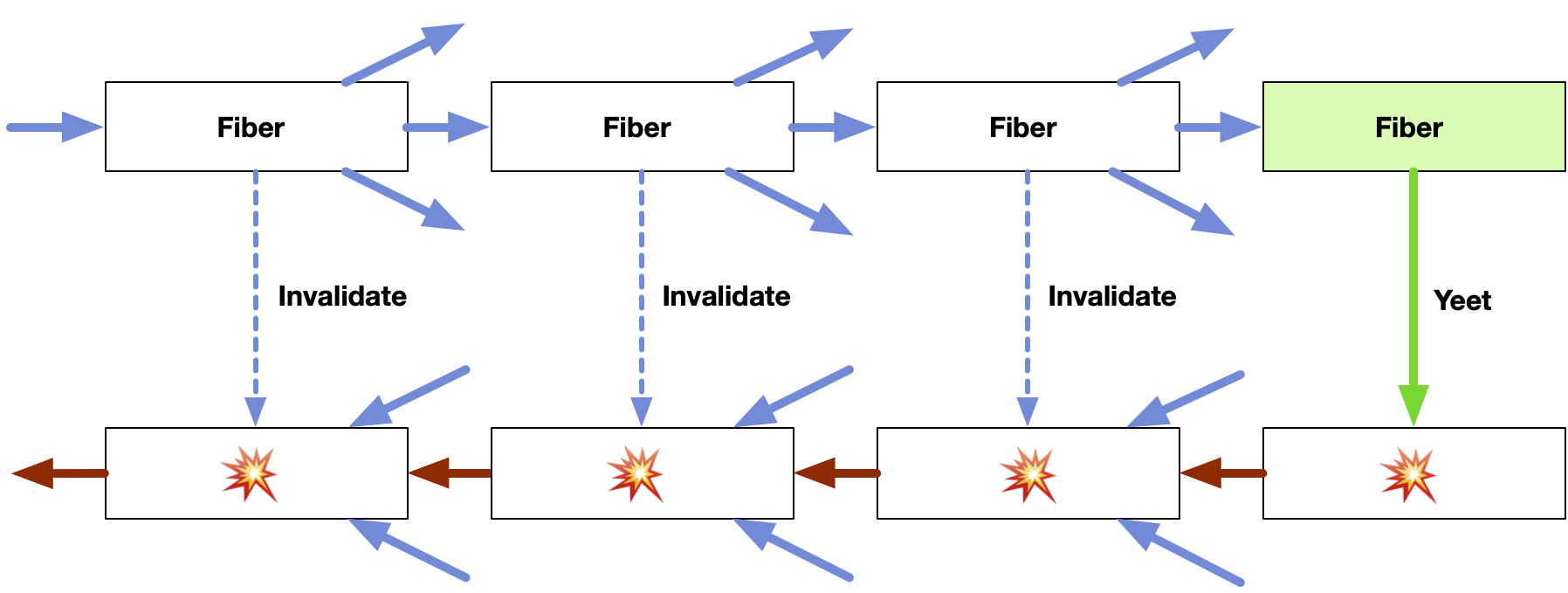
When we memoize a call in the forward direction, we will also memoize the yield in the other direction. Similarly, when we bust a cache on the near side, we also bust the paired cache on the far side, and keep busting all the way to the end. That's why it's called Yeet Reduce. Well that and yield is a reserved keyword.
What's also not obvious is that this process can be repeated: after a reduction pass is complete, we can mount a new fiber that receives the result as input. As such, the data flow graph is not a single expansion and contraction, but rather, many of them, separated by a so-called data fence.
This style of coding is mainly suited for use near the top of an application's data dependency graph, or in a shallow sub-tree, where the number of nodes in play is typically a few dozen. When you have tons of tiny objects instead, you want to rely on data-level parallelism rather than mounting each item individually.
Horse JS
I used to think a generalized solution for memoized data flow would be something crazy and mathematical. The papers I read certainly suggested so, pushing towards the equivalent of automatic differentiation of any code. It would just work. It would not require me to explicitly call memo on and in every single Component. It should not impose weird rules banning control flow. It would certainly not work well with non-reactive code. And so on.
There seemed to be an unbridgeable gap between a DFG and a stack machine. This meant that visual, graph-based coding tools would always be inferior in their ability to elegantly capture Turing-complete programs.
Neither seems to be the case. For one, having to memoize things by hand doesn't feel wrong in the long run. A minimal recomputation doesn't necessarily mean a recomputation that is actually small and fast. It feels correct to make it legible exactly how often things will change in your code, as a substitute for the horrible state transitions of old. Caching isn't always a net plus either, so fully memoized code would just be glacial for real use cases. That's just how the memory vs CPU trade-off falls these days.
That said, declaring dependencies by hand is annoying. You need linter rules for it because even experienced engineers occasionally miss a dep. Making a transpiler do it or adding it into the language seems like a good idea, at least if you could still override it. I also find <JSX> syntax is only convenient for quickly nesting static <Components> inside other <Components>. Normal JS {object} syntax is often more concise, at least when the keys match the names. Once you put a render prop in there, JSX quickly starts looking like Lisp with a hangover.
When your Components are just resources and effects instead of widgets, it feels entirely wrong that you can't just write something like:
live (arg) => {
let [service, store] = mount [
Service(...),
Store(...),
];
}
Without any JSX or effect-like wrappers. Here, mount would act somewhat like a reactive version of the classic new operator, with a built-in yield, except for fiber-mounted Components instead of classes.
I also have to admit to being sloppy here. The reason you can think of a React component as an Effect is because its ultimate goal is to create e.g. an HTML DOM. Whatever code you run exists, in theory, mostly to generate that DOM. If you take away that purpose, suddenly you have to be a lot more conscious of whether a piece of code can actually be skipped or not, even if it has all the same inputs as last time.
This isn't actually as simple as merely checking if a piece of code is side-effect free: when you use declarative patterns to interact with stateful code, like a transaction, it is still entirely contextual whether that transaction needs to be repeated, or would be idempotent and can be skipped. That's the downside of trying to graft statelessness onto legacy tech, which also requires some mutable water in your immutable wine.
I did look into writing a Babel parser for a JS/TS dialect, but it turns out the insides are crazy and it takes three days just to make it correctly parse live / mount with the exact same rules as async / await. That's because it's a chain of 8 classes, each monkey patching the previous one's methods, creating a flow that's impractical to trace step by step. Tower of Babel indeed. It's the perfect example to underscore this entire article series with.
It also bothers me that each React hook is actually pretty bad from a garbage collection point of view:
const memoized = useMemo(() => slow(foo), [foo]);
This will allocate both a new dependency array [foo] and a new closure () => slow(foo). Even if nothing has changed and the closure is not called. This is unavoidable if you want this to remain a one-liner JS API. An impractical workaround would be to split up and inline useMemo into into its parts which avoid all GC:
// One useMemo() call
let memoized;
{
useMemoNext();
useMemoPushDependency(foo);
memoized = useMemoSameDependencies() ? useMemoValue() : slow(foo);
}
But a language with a built-in reconciler could actually be quite efficient on the assembly level. Dependencies could e.g. be stored and checked in a double buffered arrangement, alternating the read and write side.
I will say this: React has done an amazing job. It got popular because its Virtual DOM finally made HTML sane to work with again. But what it actually was in the long run, was a Trojan horse for Lisp-like thinking and a move towards Effects.
No-API
So, headless React works pretty much exactly as described. Except, without the generators, because JS generators are stateful and not rewindable/resumable. So for now I have to write my code in the promise.then(…) style instead of using a proper yield.
I tried to validate it by using WebGPU as a test case, building out a basic set of composable components. First I hid the uglier parts of the WebGPU API inside some pure wrappers (the makeFoo(...) calls below) for conciseness. Then I implemented a blinking cube like this:
export const Cube: LiveComponent<CubeProps> = memo((fiber) => (props) => {
const {
device, colorStates, depthStencilState,
defs, uniforms, compileGLSL
} = props;
// Blink state, flips every second
const [blink, setBlink] = useState(0);
useResource((dispose) => {
const timer = setInterval(() => {
setBlink(b => 1 - b);
}, 1000);
dispose(() => clearInterval(timer));
});
// Cube vertex data
const cube = useOne(makeCube);
const vertexBuffers = useMemo(() =>
makeVertexBuffers(device, cube.vertices), [device]);
// Rendering pipeline
const pipeline = useMemo(() => {
const pipelineDesc: GPURenderPipelineDescriptor = {
primitive: {
topology: "triangle-list",
cullMode: "back",
},
vertex: makeShaderStage(
device,
makeShader(compileGLSL(vertexShader, 'vertex')),
{buffers: cube.attributes}
),
fragment: makeShaderStage(
device,
makeShader(compileGLSL(fragmentShader, 'fragment')),
{targets: colorStates}
),
depthStencil: depthStencilState,
};
return device.createRenderPipeline(pipelineDesc);
}, [device, colorStates, depthStencilState]);
// Uniforms
const [uniformBuffer, uniformPipe, uniformBindGroup] = useMemo(() => {
const uniformPipe = makeUniforms(defs);
const uniformBuffer = makeUniformBuffer(device, uniformPipe.data);
const entries = makeUniformBindings([{resource: {buffer: uniformBuffer}}]);
const uniformBindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries,
});
return ([uniformBuffer, uniformPipe, uniformBindGroup]
as [GPUBuffer, UniformDefinition, GPUBindGroup]);
}, [device, defs, pipeline]);
// Return a lambda back to parent(s)
return yeet((passEncoder: GPURenderPassEncoder) => {
// Draw call
uniformPipe.fill(uniforms);
uploadBuffer(device, uniformBuffer, uniformPipe.data);
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, uniformBindGroup);
passEncoder.setVertexBuffer(0, vertexBuffers[0]);
passEncoder.draw(cube.count, 1, 0, 0);
});
}
This is 1 top-level function, with zero control flow, and a few hooks. The cube has a state (blink), that it decides to change on a timer. Here, useResource is like a sync useEffect which the runtime will manage for us. It's not pure, but very convenient.
All the external dependencies are hooked up, using the react-like useMemo hook and its mutant little brother useOne (for 0 or 1 dependency). This means if the WebGPU device were to change, every variable that depends on it will be re-created on the next render. The parts that do not (e.g. the raw cube data) will be reused.
This by itself is remarkable to me: to be able to granularly bust caches like this deep inside a program, written in purely imperative JS, that nevertheless is almost a pure declaration of intent. When you write code like this, you focus purely on construction, not on mutation. It also lets you use an imperative API directly, which is why I refer to this as "No API": the only wrappers are those which you want to add yourself.
Notice the part at the end: I'm not actually yeeting a real draw command. I'm just yeeting a lambda that will insert a draw command into a vanilla passEncoder from the WebGPU API. It's these lambdas which are reduced together in this sub-tree. These can then just be run in tree order to produce the associated render pass.
What's more, the only part of the entire draw call that actually changes regularly is the GPU uniform values. This is why uniforms is not an immutable object, but rather an immutable reference with mutable registers inside. In react-speak it's a ref, aka a pointer. This means if only the camera moves, the Cube component does not need to be re-evaluated. No lambda is re-yeeted, and nothing is re-reduced. The same code from before would keep working.
Therefor the entirety of Cube() is wrapped in a memo(...). It memoizes the entire Component in one go using all the values in props as the dependencies. If none of them changed, no need to do anything, because it cannot have any effect by construction. The run-time takes advantage of this by not re-evaluating any children of a successfully memoized node, unless its internal state changed.
The very top of the (reactive) part is:
export const App: LiveComponent<AppProps> = () => (props) => {
const {canvas, device, adapter, compileGLSL} = props;
return use(AutoCanvas)({
canvas, device, adapter,
render: (renderContext: CanvasRenderingContextGPU) => {
const {
width, height, gpuContext,
colorStates, colorAttachments,
depthStencilState, depthStencilAttachment,
} = renderContext;
return use(OrbitControls)({
canvas,
render: (radius: number, phi: number, theta: number) =>
use(OrbitCamera)({
canvas, width, height,
radius, phi, theta,
render: (defs: UniformAttribute[], uniforms: ViewUniforms) =>
use(Draw)({
device, gpuContext, colorAttachments,
children: [
use(Pass)({
device, colorAttachments, depthStencilAttachment,
children: [
use(Cube)({device, colorStates, depthStencilState, compileGLSL, defs, uniforms}),
]
})
],
})
})
});
}
});
};
This is a poor man's JSX, but also not actually terrible. It may not look like much, but, pretty much everyone who's coded any GL, Vulkan, etc. has written a variation of this.
This tree composes things that are completely heterogeneous: a canvas auto-sizer, interactive controls, camera uniforms, frame buffer attachments, and more, into one neat, declarative structure. This is quite normal in React-land these days. The example above is static to keep things simple, but it doesn't need to be, that's the point.
The nicest part is that unlike in a traditional GPU renderer, it is trivial for it to know exactly when to re-paint the image or not. Even those mutable uniforms come from a Live component, the effects of which are tracked and reconciled: OrbitCamera takes mutable values and produces an immutable container ViewUniforms.
You get perfect battery-efficient sparse updates for free. It's actually more work to get it to render at a constant 60 fps, because for that you need the ability to independently re-evaluate a subtree during a requestAnimationFrame(). I had to explicitly add that to the run-time. It's around 1100 lines now, which I'm happy with.
Save The Environment
If it still seems annoying to have to pass variables like device into everything, there's the usual solution: context providers, aka environments, which act as invisible skip links across the tree:
export const GPUDeviceContext = makeContext();
export const App: LiveComponent<AppProps> = () => (props) => {
const {canvas, device, adapter, compileGLSL} = props;
return provide(GPUDeviceContext, device,
use(AutoCanvas)({ /*...*/ })
);
}
export const Cube: LiveComponent<CubeProps> = memo((fiber) => (props) => {
const device = useContext(GPUDeviceContext);
/* ... */
}
You also don't need to pass one variable at a time, you can pass arbitrary structs.
In this situation it is trickier for the run-time to track changes, because you may need to skip past a memo(…) parent that didn't change. But doable.
Yeet-reduce is also a generalization of the chunking and clustering processes of a modern compute-driven renderer. That's where I got it from anyway. Once you move that out, and make it a native op on the run-time, magic seems to happen.
This is remarkable to me because it shows you how you can wrap, componentize and memoize a completely foreign, non-reactive API, while making it sing and dance. You don't actually have to wrap and mount a <WebGPUThingComponent> for every WebGPUThing that exists, which is the popular thing to do. You don't need to do O(N) work to control the behavior of N foreign concepts. You just wrap the things that make your code more readable. The main thing something like React provides is a universal power tool for turning things off and on again: expansion, memoization and reconciliation of effects. Now you no longer need to import React and pretend to be playing DOM-jot either.
The only parts of the WebGPU API that I needed to build components for to pull this off, were the parts I actually wanted to compose things with. This glue is so minimal it may as well not be there: each of AutoSize, Canvas, Cube, Draw, OrbitCamera, OrbitControls and Pass is 1 reactive function with some hooks inside, most of them half a screen.
I do make use of some non-reactive WebGPU glue, e.g. to define and fill binary arrays with structured attributes. Those parts are unremarkable, but you gotta do it.
If I now generalize my Cube to a generic Mesh, I have the basic foundation of a fully declarative and incremental WebGPU toolkit, without any OO. The core components look the same as the ones you'd actually build for yourself on the outside. Its only selling point is a supernatural ability to get out of your way, which it learnt mainly from React. It doesn't do anything else. It's great when used to construct the outside of your program, i.e. the part that loads resources, creates workloads, spawns kernels, and so on. You can use yeet-reduce on the inside to collect lambdas for the more finicky stuff, and then hand the rest of the work off to traditional optimized code or a GPU. It doesn't need to solve all your problems, or even know what they are.
I should probably reiterate: this is not a substitute for typical data-level parallelism, where all your data is of the exact same type. Instead it's meant for composing highly heterogeneous things. You will still want to call out to more optimized code inside to do the heavy lifting. It's just a lot more straightforward to route.
For some reason, it is incredibly difficult to get this across. Yet algorithmically there is nothing here that hasn't been tried before. The main trick is just engineering these things from the point of view of the person who actually has to use it: give them the same tools you'd use on the inside. Don't force them to go through an interface if there doesn't need to be one.
The same can be said for React and Live, naturally. If you want to get nerdy about it, the reconciler can itself be modeled as a live effect. Its actions can themselves become regular nodes in the tree. If there were an actual dialect with a real live keyword, and WeakMaps on steroids, that would probably be doable. In the current implementation, it would just slow things down.
Throughout this series, I've used Javascript syntax as a lingua franca. Some might think it's insane to stretch the language to this point, when more powerful languages exist where effects fit more natively into the syntax and the runtime. I think it's better to provide stepping stones to actually get from here to there first.
I know that once you have gone through the trouble of building O(N2) lines of code for something, and they work, the prospect of rewriting all of them can seem totally insane. It probably won't be as optimized on the micro-level, which in some domains does actually still matter, even in this day and age. But how big is that N? It may actually be completely worth it, and it may not take remotely as long as you think.
As for me, all I had to do was completely change the way I structure all my code, and now I can finally start making proper diagrams.
Source code on GitLab.