
Climbing Mount Effect

Declarative Code and Effects
This is a series about incrementalism in code and coding. On the one hand, I mean code that is rewindable and resumable. On the other, I mean incremental changes in how we code.
This is not an easy topic, because understanding some of the best solutions requires you to see the deep commonalities in code across different use cases. So I will deliberately start from basic principles and jump a few domains. Sorry, it's unavoidable.
Hopefully by the end, you will look differently at the code you write. If you don't, I hope it's because you already knew all this.
- Part 1: Climbing Mount Effect - Declarative Code and Effects
- Part 2: Reconcile All The Things - Memoization, Data Flow and Reconciliation
- Part 3: Headless React - Live, Yeet Reduce, No-API, WebGPU
Hello World
If an abstraction is good enough to be adopted, it tends to make people forget why it was necessary to invent it in the first place. Declarative code is such an abstraction.
The meaning of "declarative code" is often defined through contrast: code that is not imperative or Object-Oriented. This is not very useful, because you can use declarative patterns all over imperative code, and get the exact same benefits. It can also be a great way to tame wild code you don't own, provided you can build the right glue.
Declarative + OO however is a different story, and this applies just the same to OO-without-classes. Mind you, this has nothing to do with the typical endless debate between FP vs OO, which is the one about extensibility vs abstract data types. That's unrelated.
While seeing wide adoption in certain niches (e.g. UI), the foundational practices of declarative code are often poorly understood. As a result, coders tend to go by example rather than principle: do whatever the existing code does. If they need to stray from the simple paths, they easily fall into legacy habits, resulting in poorly performing or broken code.
So far the best solution is to use linters to chide them for using things as they were originally intended. The better solution is to learn exactly when to say No yourself. The most important thing to understand is the anti-patterns that declarative code is supposed to remedy. Headache first, then aspirin.

For a perfect example, see the patch notes for almost any complex video game sandbox. They often contain curious, highly specific bugs:
- Fix crouch staying on if used while a bear attacks
- Fix player getting control-locked if loading an autosave created while lockpicking
- Fix a bug which lets you immediately cancel a knockdown by swapping ammo types
- Fixed an issue where leaving and returning after the briefing would block the quest's progress
Some combination of events or interactions corrupts the game's state in some way. Something changed when it shouldn't have, or the other way around. In the best case this results in a hilarious glitch, in the worst case a permanently unfinishable game. Developers can spend months chasing down weird bugs like this. It turns into whack-a-mole, as each new fix risks breaking other things.
This is very different from issues that occur when the game systems do exactly what they should do. Like that time cats were getting alcohol poisoning in Dwarf Fortress, because they had walked through puddles of spilled beer in the pub, and licked themselves clean afterwards. Such a complex chain of causality may be entirely unanticipated, but it's readily apparent why it happens. It's the result of code working too well.
Part of me dies every time I see a game get stuck in the mud instead, when I really want to see them succeed: I have a pretty good idea of the mess they've created for themselves, and why it's probably only going to get worse. Unless they dramatically refactor. Which usually isn't an option.
It's Imperative
So why does this happen?
Imagine an App with 5 views in tabs. Only one view is visible at a time, so there are 5 possible states. Because you can switch from any tab to any other, there are 5 x 4 = 20 possible state changes.
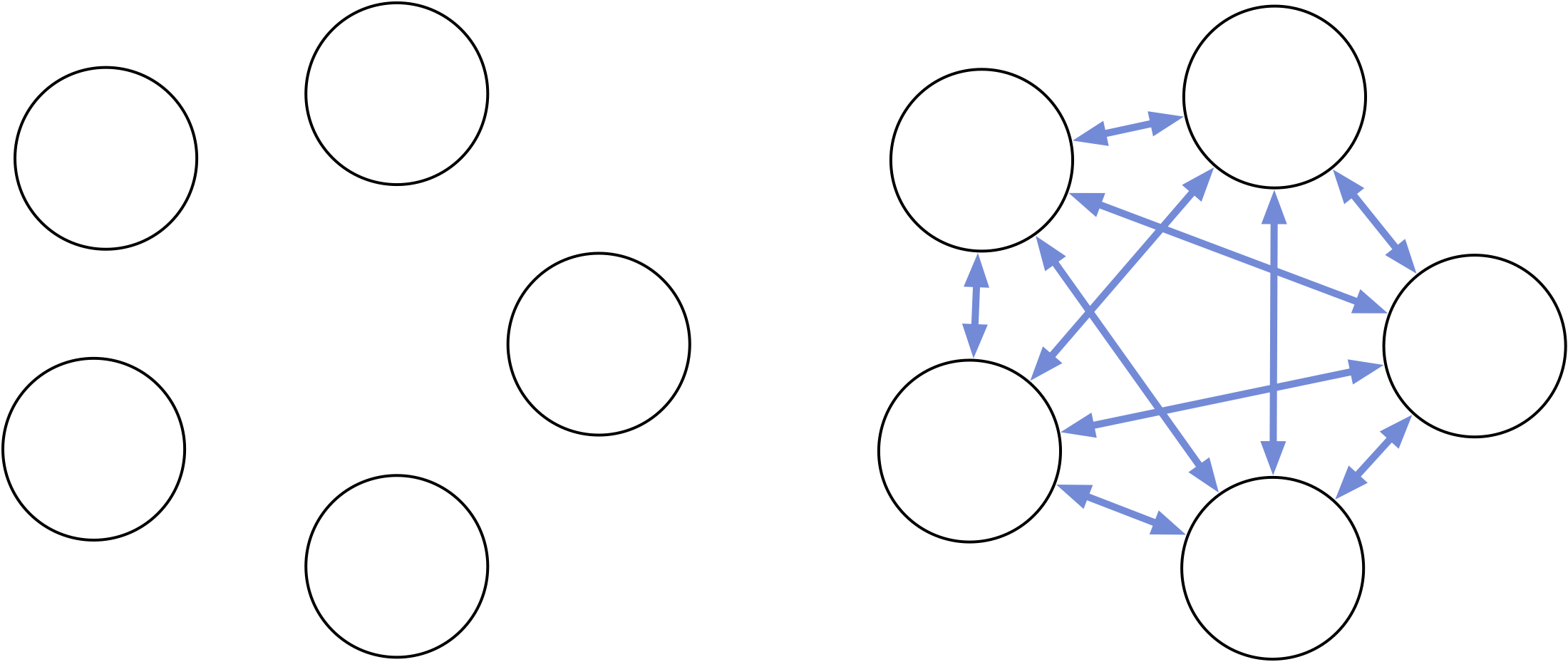
So you might imagine some code that goes:
constructor() {
this.currentView = HomeView;
}
onSelect(newView) {
// Hide selected view (exit old state)
this.currentView.visible = false;
// Show new view (enter new state)
newView.visible = true;
this.currentView = newView;
}
This will realize the arrows in the diagram for each pair of currentView and newView.
But wait. Design has decided that when you switch to the Promotions tab, it should start auto-playing a video. And it needs to stop playing if you switch away. Otherwise it will keep blaring in the background, which is terrible:
onSelect(newView) {
if (this.currentView == newView) return;
// Exit old state
this.currentView.visible = false;
if (this.currentView == PromoView) {
PromoView.video.stop();
}
// Enter new state
newView.visible = true;
if (newView == PromoView) {
PromoView.video.play();
}
this.currentView = newView;
}
No wait, they want it to keep playing in the background if you switch to the Social tab and back.
onSelect(newView) {
if (this.currentView == newView) return;
// Exit old state
this.currentView.visible = false;
if ((this.currentView == PromoView && newView != SocialView) ||
(this.currentView == SocialView && newView != PromoView)) {
PromoView.video.pause();
}
// Enter new state
newView.visible = true;
if (newView == PromoView) {
PromoView.video.play();
}
currentView = newView;
}
Ok. Now they want to add a Radio tab with a podcast player, and they want it to auto play too. But only if the promo video isn't already playing.
Just look at how the if statements are popping out of the ground like mushrooms. This is the point at which things start to go terminally wrong. As features are piled on, a simple click handler explodes into a bloated mess. It's difficult to tell or test if it's even right, and there will likely be bugs and fixes. Replace the nouns and verbs, and you will get something very similar to what caused the curious bugs above.
The problem is that this code is written as delta-code (*). It describes state changes, rather than the states themselves. Because there are O(N2) arrows, there will potentially be O(N2) lines of code for dealing with N states. Each new feature or quirk you add will require more work than before, because it can interact with all the existing ones.
So imperative code isn't a problem by itself. The issue is code that becomes less maintainable over time. Ironically, a software industry notorious for snooty whiteboard interviews spent decades writing code like an O(N2) algorithm.
The real reason to write declarative code is to produce code that is O(N) lines instead. This work does not get harder over time. This is generally not taught in school because neither the students nor their teachers have spent enough time in one continuous codebase. You need to understand the O(N2) > O(N) part of the curve to know why it's so terrible, especially in the real world.
It probably seemed attractive in the first place, because it seemed economical to only touch the state that was changing. But this aversion to wasted CPU cycles has to be seriously traded off against the number of wasted human cycles.
Better to write code that makes it impossible to reach a bad state in the first place. Easier said than done, of course. But you should start with something like:
let tabs = [
{
view: homeView,
}
{
view: promoView,
video: 'promo-video.mp4',
autoplayVideo: true,
},
{
view: socialView,
backgroundVideo: true,
},
{
view: newsView,
video: 'news-video.mp4',
autoplayVideo: true,
},
// ...
]
If you need to add a new kind of tab quirk, you define 1 new flag. You set it on a constant number of tabs, and then write the code to handle that quirk in 1 place. O(1) work. This code also tells you exactly where and what the special exceptions are, in one place, which means another engineer can actually understand it at a glance.
The declarative approach to visibility is just to blindly show or hide every tab in a plain old loop, instead of caring about what needs to go away and what needs to come in. When somebody inevitably wants the tabs to animate in and out—an animation which can be interrupted—you will discover that is actually what you have to do in the general case anyway.
Same with the video: you declare which one is currently supposed to be playing. Then you compare new with old, to see if you need to replace, pause, or adopt the current video.
The goal is to have most code only declare intent. Then you use other code to reach that target, no matter what the prior state was.
In some circles this is all old hat. But I suspect the people writing the hot frameworks don't quite realize how alien these problems feel from the outside. If the run-time is invisible, how are you ever supposed to figure out how it works, and learn to apply those same tricks? And how do you reach declarative bliss when there isn't a nice, prepackaged solution for your particular domain yet?
Or maybe there is a very capable library, but it's written in a retained style. If you try to fit this into declarative code without a proper adapter, you will end up writing delta-code all over again.
Strange Effects
The underlying challenge here is as banal as it is important and universal: "Have you tried turning it off and on again?"
Code is Turing-complete, so you don't know what it's going to do until you run it. It has the ability to amplify the complexity of its inputs. So if you change some of them, which parts are going to switch on and which will switch off?
Even on the back-end, similar things crop up behind the scenes:
- connecting and disconnecting to network peers
- starting and stopping jobs in response to events
- building indices of data being edited
- watching file systems for changes
- allocating and freeing memory for data
These are all state transitions of some kind, which are usually orchestrated by hand.
Take the job of creating and managing a dependent resource inside a class. I swear I have seen this code written in dozens of codebases, each with dozens of files all doing the same thing, including one of my own:
constructor(size) {
this.size = size;
this.thing = new Thing(this.size);
}
onUpdate() {
if (this.thing.size != this.size) {
this.thing.dispose();
this.thing = new Thing(this.size);
}
}
dispose() {
if (this.thing) this.thing.dispose();
}
This general pattern is:
constructor() {
// Enter state - on
}
onUpdate() {
// Exit old state - off
// Enter new state - on
}
dispose() {
// Exit state - off
}
You have to write code in 3 separate places in order to create, maintain and dispose of 1 thing. This code must also have access to this, in order to mutate it. Look around and you will see numerous variations of this pattern. Whenever someone has to associate data with a class instance whose lifecycle they do not fully control, you will likely spot something like this.
The trick to fix it is mainly just slicing the code differently, e.g. using a generator:
let effect1 = function* () {
// Enter state - on
yield // Wait
// Exit state - off
}
let effect2 = function* () {
// Enter state - on
yield // Wait
// Exit state - off
}
There are now only 2 identically shaped functions, each of which only refers to 1 state, not the previous nor next. A yield allows the function to be interrupted mid-call. The idea here is to simplify the lifecycle:
From
- constructor()
- onUpdate()
- onUpdate()
- onUpdate()
- dispose()
To
- Call effect
- Cleanup effect
- Call effect
- Cleanup effect
- Call effect
- Cleanup effect
- Call effect
- Cleanup effect
- Call effect
- Cleanup effect
It doesn't have fewer calls, just fewer unique parts. It might seem dramatically less useful, but it's actually mostly the opposite. Though this is not obvious at first.
If you don't have a good mental model of a generator, you can pretend that instead it says:
let effect = () => {
// Enter state - on
return {
// I'm not done yet
done: false,
// I don't have a value to return
value: undefined,
// Call me 🤙
next: () => {
// Exit state - off
return {done: true, value: undefined}
}
};
}
This code could be described as self-rewinding: it creates something and then disposes of it. We can make a function that produces Thing resources this way:
// This creates an effect that describes the lifecycle of a Thing of size
let makeThingEffect = (size) => function* () {
// Make thing
thing = new Thing(size);
yield thing;
// Dispose thing
thing.dispose();
};
So let's first talk about just effects as a formal type. They are similar to async/await and promises. But effects and promises are subtly different. A promise represents ongoing work. An effect is merely a description of work.
The difference is:
- In a promise-based API,
fetch(url) => Promisewill run a new HTTP request - In an effect-based API,
fetch(url) => Effectwill describe an HTTP request
As a first approximation, you can think of an effect-based API as:
fetch(url) => () => Promise
It won't actually start until you call it a second time. Why would you need this?
Suppose you want to implement an auto-retry mechanism for failed requests. If a fetch promise fails, there is no way for you to retry using the promise itself. Each is one-use-only. You have to call fetch(url) again to get a fresh one. You need to know the specific type of promise and its arguments.
But if a fetch effect fails, then you can retry the same effect just by passing it back to your effect run-time. You don't need to know what effect it is. So in an Effect-based API, you can make a universal attemptRetry(effect, N) in a few lines. To emulate this with Promises, you need to use a () => Promise instead.
However, real Effects are supposed to be chained together, passing data from start to end. This is either a value or an error, to another effect, or back to the calling context. e.g.:
let makeAnEffect = (nextEffect) => function* (input, error) {
if (!error) {
output = f(input);
return [nextEffect, output];
}
else return [null, null, error];
}
let combinedEffect = makeAnEffect( makeAnEffect( makeAnEffect() ) );
Here we return a static nextEffect that was decided on effect construction, along with a successful output to pass along. Or, if an error happened, we stop and only return the error. combinedEffect means running it 3 times in a row.
You could also return arbitrary effects on the fly. Below is a retry combinator. If an error happens, it returns another copy of itself, but with the retry count reduced by 1, until it reaches 0:
let attemptRetry = (effect, n) => function* (i, e) {
// Make request
const [value, error] = yield [effect, i, e];
// Success
if (value) return [null, value];
// Retry n times
if (n > 0) return attemptRetry(effect, n - 1);
// Abort
return [null, null, error];
}
This is 1 function in 1 place you can use anywhere.
You can focus purely on defining and declaring intended effects, while letting a run-time figure out how to schedule and execute them. In essence, an Effect is a formalization of 🤙 aka (...) =>. It's about the process of making things happen, not the actions themselves.
Whether effects are run serially or parallel depends on the use case, just like promises. Whether an effect should actually be disposed of or undone is also contextual: if it represents an active resource, then disposal is necessary to ensure a clean shutdown. But if an effect is part of a transaction, then you should only be rolling it back if the effect chain failed.
Other people have different definitions, and some of their Effects do different or fancier things. So buyer beware. But know that even just () => Promise, () => Generator and () => void can solve a whole bunch of issues elegantly.
Disposable
Going back to the makeThingEffect above, it might still seem overkill to wrap a "classic OO" class like new Thing this way. What's wrong with just having an interface Disposable that you implement/inherit from? Why should you want to box in OO code with effects even if you don't need to compose them? The difference is subtle.
For reliable operation, it's desirable that completion of one effect or disposal of a resource happens before the next one starts (i.e. to avoid double-allocating memory). But you can't call new on a class without immediately running a constructor. So you can't hold both an old and a new instance in your hands, so to speak, without having already initialized and run the new one. A common workaround is to have an empty constructor and delegate to an init() instead. This means some (or all) of your classes are non-standard to use, and you've reinvented the native new and delete.
Often you wish to retain some resources across a change, for efficiency, which means you need a hand-coded onChange() to orchestrate that. The main way you will take care of a series of possible creations and disposals is to just write new Thing and if (this.thing) and this.thing.foo != this.foo code repeatedly. That's why I've seen this code a thousand times.
While you can easily create a central mechanism for tracking disposals with classic OO, it's much harder to create a mechanism that handles both creation and updates. Somebody has to invoke specific constructors or reallocators, on specific classes, with specific arguments. This is called a Factory, and they pretty much suck.
It might seem like effects don't address this at all, as the pure form forbids any retention of state from one effect to the next, with each thing created in isolation. But it totally works: if every resource is wrapped in its own effect, you can declare the data dependencies per resource too. You can say "only re-allocate this resource if ____ or ____ changed since last time."
Instead of having an init() and an onChange() that you write by hand, you just have a render() method which spawns N resources and their dependencies. The run-time will figure out which ones are stale, clean them up, and create replacements.
How to actually do this depends on your usage. If the resource needs to be available immediately, that is different from whether it only needs to be returned to other parts of the code. In the latter case, you can just return effects which haven't run yet. In the former case, well, maybe we can fix that later.
Building an "Effect run-time" sounds intimidating but 90% of the benefit here comes from giving yourself the ability to put your "exit" code below your "enter" code, where it belongs. Which ever way you can. Then there only needs to be 1 place in your code where "exit" appears above "enter" (i.e. an onUpdate), which you only have to write once. O(1).
At least that's the dream. I know I'm still handwaving a lot. It's entirely on purpose. In practice, unless you have a fixed structure to hang your effects and resources off of, it's actually quite hard to track all the associated state. You simply don't have anywhere specific to put it. Where does yield thing go, actually?
The potential benefits here are so enormous, that it's absolutely worth to figure this out.
More tomorrow.
(*) hat-tip James Crook for this term