Using Web APIs for Research
Recently we launched our new product at Strutta, a 'create your own contest site' web service. In each contest, users submit and vote on each other's videos, pictures, songs or writings.
As part of the research we did for the development, we wanted to examine our competition. So, I dove into YouTube to try and figure out some of their ideas and algorithms. For me, this wasn't entirely new: when I posted my Line Rider videos to YouTube, I followed up each video with manual statistics tracking and gained some insight into how a video becomes popular on YouTube. However, that only gave me a very narrow view of the community and its dynamics.
Since then though, things have changed a lot. YouTube now has a public API as well as pre-made libraries to use. With these, it becomes very easy to collect statistics and perform your own analysis. So, armed with Python, I set out to investigate YouTube's ubiquitous 'related videos' feature.
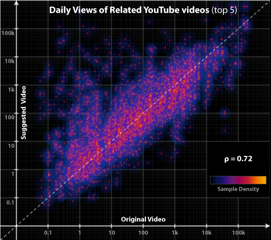
I found it interesting to analyse a big site through their own API rather than screen scraping. Traditionally, one first tries to collect as much data as possible, but the resulting data set can become very unwieldy. In this case, I already had full access and I could focus on exactly which queries I wanted to run, how to aggregate my data, and which measures to focus on.
The results revealed some interesting conclusions. My big write-up can be found on the Strutta Blog, aptly titled Six Degrees of YouTube.