Fuck It, We'll Do It Live
How the Live effect run-time is implemented

In this post I describe how the Live run-time internals are implemented, which drive Use.GPU. Some pre-existing React and FP effect knowledge is useful.
I have written about Live before, but in general terms. You may therefor have a wrong impression of this endeavor.
When a junior engineer sees an application doing complex things, they're often intimidated by the prospect of working on it. They assume that complex functionality must be the result of complexity in code. The fancier the app, the less understandable it must be. This is what their experience has been so far: seniority correlates to more and hairier lines of code.
After 30 years of coding though, I know it's actually the inverse. You cannot get complex functionality working if you've wasted all your complexity points on the code itself. This is the main thing I want to show here, because this post mainly describes 1 data structure and a handful of methods.
Live has a real-time inspector, so a lot of this can be demonstrated live. Reading this on a phone is not recommended, the inspector is made for grown-ups.
The story so far:
The main mechanism of Live is to allow a tree to expand recursively like in React, doing breadth-first expansion. This happens incrementally, and in a reactive, rewindable way. You use this to let interactive programs knit themselves together at run-time, based on the input data.
Like a simple CLI program with a main() function, the code runs top to bottom, and then stops. It produces a finite execution trace that you can inspect. To become interactive and to animate, the run-time will selectively rewind, and re-run only parts, in response to external events. It's a fusion of immediate and retained mode UI, offering the benefits of both and the downsides of neither, not limited to UI.
This relies heavily on FP principles such as pure functions, immutable data structures and so on. But the run-time itself is very mutable: the whole idea is to centralize all the difficult parts of tracking changes in one place, and then forget about them.
Live has no dependencies other than a JavaScript engine and these days consists of ~3600 lines.
If you're still not quite sure what the Live component tree actually is, it's 3 things at once:
- a data dependency graph
- an execution trace
- a tree-shaped cache
The properties of the software emerge because these aspects are fully aligned inside a LiveComponent.
Functionally Mayonnaise
You can approach this from two sides, either from the UI side, or from the side of functional Effects.
Live Components
A LiveComponent (LC) is a React UI function component (FC) with 1 letter changed, at first:
const MyComponent: LC<MyProps> = (props: MyProps) => {
const {wat} = props;
// A memo hook
// Takes dependencies as array
const slow = useMemo(() => expensiveComputation(wat), [wat]);
// Some local state
const [state, setState] = useState(1);
// JSX expressions with props and children
// These are all names of LC functions to call + their props/arguments
return (
<OtherComponent>
<Foo value={slow} />
<Bar count={state} setCount={setState} />
</OtherComponent>
);
};The data is immutable, and the rendering appears stateless: it returns a pure data structure for given input props and current state. The component uses hooks to access and manipulate its own state. The run-time will unwrap the outer layer of the <JSX> onion, mount and reconcile it, and then recurse.
let _ = await (
<OtherComponent>
<Foo foo={foo} />
<Bar />
</OtherComponent>
);
return null;
The code is actually misleading though. Both in Live and React, the return keyword here is technically wrong. Return implies passing a value back to a parent, but this is not happening at all. A parent component decided to render <MyComponent>, yes. But the function itself is being called by Live/React. it's yielding JSX to the Live/React run-time to make a call to OtherComponent(...). There is no actual return value.
Because a <Component> can't return a value to its parent, the received _ will always be null too. The data flow is one-way, from parent to child.
Effects
An Effect is basically just a Promise/Future as a pure value. To first approximation, it's a () => Promise: a promise that doesn't actually start unless you call it a second time. Just like a JSX tag is like a React/Live component waiting to be called. An Effect resolves asynchronously to a new Effect, just like <JSX> will render more <JSX>. Unlike a Promise, an Effect is re-usable: you can fire it as many times as you like. Just like you can keep rendering the same <JSX>.
let value = yield (
OtherEffect([
Foo(foo),
Bar(),
])
);
// ...
return value;
So React is like an incomplete functional Effect system. Just replace the word Component with Effect. OtherEffect is then some kind of decorator which describes a parallel dispatch to Effects Foo and Bar. A real Effect system will fork, but then join back, gathering the returned values, like a real return statement.
Unlike React components, Effects are ephemeral: no state is retained after they finish. The purity is actually what makes them appealing in production, to manage complex async flows. They're also not incremental/rewindable: they always run from start to finish.
| Pure | Returns | State | Incremental | |
|---|---|---|---|---|
| React | ✅ | ❌ | ✅ | ✅ |
| Effects | ✅ | ✅ | ❌ | ❌ |
You either take an effect system and make it incremental and stateful, or you take React and add the missing return data path
I chose the latter option. First, because hooks are an excellent emulsifier. Second, because the big lesson from React is that plain, old, indexed arrays are kryptonite for incremental code. Unless you've deliberately learned how to avoid them, you won't get far, so it's better to start from that side.
This breakdown is divided into three main parts:
- the rendering of 1 component
- the environment around a component
- the overall tree update loop
Components
The component model revolves around a few core concepts:
- Fibers
- Hooks and State
- Mounts
- Memoization
- Inlining
Components form the "user land" of Live. You can do everything you need there without ever calling directly into the run-time's "kernel".
Live however does not shield its internals. This is fine, because I don't employ hundreds of junior engineers who would gleefully turn that privilege into a cluster bomb of spaghetti. The run-time is not extensible anyhow: what you see is what you get. The escape hatch is there to support testing and debugging.
Shielding this would be a game of hide-the-reference, creating a shadow-API for privileged friend packages, and so on. Ain't nobody got time for that.
React has an export called DONT_USE_THIS_OR_YOU_WILL_BE_FIRED, Live has THIS_WAY___IF_YOU_DARE and it's called useFiber.
Fibers
Borrowing React terminology, a mounted Component function is called a fiber, despite this being single threaded.
Each persists for the component lifetime. To start, you call render(<App />). This creates and renders the first fiber.
type LiveFiber = {
// Fiber ID
id: number,
// Component function
f: Function,
// Arguments (props, etc.)
args: any[],
// ...
}
Fibers are numbered with increasing IDs. In JS this means you can create 253 fibers before it crashes, which ought to be enough for anybody.
It holds the component function f and its latest arguments args. Unlike React, Live functions aren't limited to only a single props argument.
Each fiber is rendered from a <JSX> tag, which is a plain data structure. The Live version is very simple.
type Key = number | string;
type JSX.Element = {
// Same as fiber
f: Function,
args: any[],
// Element key={...}
key?: string | number,
// Rendered by fiber ID
by: number,
}
Another name for this type is a DeferredCall. This is much leaner than React's JSX type, although Live will gracefully accept either. In Live, JSX syntax is also optional, as you can write use(Component, …) instead of <Component … />.
Calls and fibers track the ID by of the fiber that rendered them. This is always an ancestor, but not necessarily the direct parent.
fiber.bound = () => {
enterFiber(fiber);
const {f, args} = fiber;
const jsx = f(...args);
exitFiber(fiber);
return jsx;
};
The fiber holds a function bound. This binds f to the fiber itself, always using the current fiber.args as arguments. It wraps the call in an enter and exit function for state housekeeping.
This can then be called via renderFiber(fiber) to get jsx. This is only done during an ongoing render cycle.
{
// ...
state: any[],
pointer: number,
}
Hooks and State
Each fiber holds a local state array and a temporary pointer:
Calling a hook like useState taps into this state without an explicit reference to it.
In Live, this is implemented as a global currentFiber variable, combined with a local fiber.pointer starting at 0. Both are initialized by enterFiber(fiber).
The state array holds flattened triplets, one per hook. They're arranged as [hookType, A, B]. Values A and B are hook-specific, but usually hold a value and a dependencies array. In the case useState, it's just the [value, setValue] pair.
The fiber.pointer advances by 3 slots every time a hook is called. Tracking the hookType allows the run-time to warn you if you call hooks in a different order than before.
The basic React hooks don't need any more state than this and can be implemented in ~20 lines of code each. This is useMemo:
export const useMemo = <T>(
callback: () => T,
dependencies: any[] = NO_DEPS,
): T => {
const fiber = useFiber();
const i = pushState(fiber, Hook.MEMO);
let {state} = fiber;
let value = state![i];
const deps = state![i + 1];
if (!isSameDependencies(deps, dependencies)) {
value = callback();
state![i] = value;
state![i + 1] = dependencies;
}
return value as unknown as T;
}
useFiber just returns currentFiber and doesn't count as a real hook (it has no state). It only ensures you cannot call a hook outside of a component render.
export const useNoHook = (hookType: Hook) => () => {
const fiber = useFiber();
const i = pushState(fiber, hookType);
const {state} = fiber;
state![i] = undefined;
state![i + 1] = undefined;
};
No-hooks like useNoMemo are also implemented, which allow for conditional hooks: write a matching else branch for any if. To ensure consistent rendering, a useNoHook will dispose of any state the useHook had, rather than just being a no-op. The above is just the basic version for simple hooks without cleanup.
This also lets the run-time support early return cleanly in Components: when exitFiber(fiber) is called, all remaining unconsumed state is disposed of with the right no-hook.
If someone calls a setState, this is added to a dispatch queue, so changes can be batched together. If f calls setState during its own render, this is caught and resolved within the same render cycle, by calling f again. A setState which is a no-op is dropped (pointer equality).
You can see however that Live hooks are not pure: when a useMemo is tripped, it will immediately overwrite the previous state during the render, not after. This means renders in Live are not stateless, only idempotent.
This is very deliberate. Live doesn't have a useEffect hook, it has a useResource hook that is like a useMemo with a useEffect-like disposal callback. While it seems to throw React's orchestration properties out the window, this is not actually so. What you get in return is an enormous increase in developer ergonomics, offering features React users are still dreaming of, running off 1 state array and 1 pointer.
Live is React with the training wheels off, not with holodeck security protocols disabled, but this takes a while to grok.

Mounts
After rendering, the returned/yielded <JSX> value is reconciled with the previous rendered result. This is done by updateFiber(fiber, value).
New children are mounted, while old children are unmounted or have their args replaced. Only children with the same f as before can be updated in place.
{
// ...
// Static mount
mount?: LiveFiber,
// Dynamic mounts
mounts?: Map<Key, LiveFiber>,
lookup?: Map<Key, number>,
order?: Key[],
// Continuation
next?: LiveFiber,
// Fiber type
type?: LiveComponent,
// ...
}
Mounts are tracked inside the fiber, either as a single mount, or a map mounts, pointing to other fiber objects.
The key for mounts is either an array index 0..N or a user-defined key. Keys must be unique.
The order of the keys is kept in a list. A reverse lookup map is created if they're not anonymous indices.
The mount is only used when a component renders 1 other statically. This excludes arrays of length 1. If a component switches between mount and mounts, all existing mounts are discarded.
Continuations are implemented as a special next mount. This is mounted by one of the built-in fenced operators such as <Capture> or <Gather>.
In the code, mounting is done via:
mountFiberCall(fiber, call)(static)reconcileFiberCalls(fiber, calls)(dynamic)mountFiberContinuation(fiber, call)(next).
Each will call updateMount(fiber, mount, jsx, key?, hasKeys?).
If an existing mount (with the same key) is compatible it's updated, otherwise a replacement fiber is made with makeSubFiber(…). It doesn't update the parent fiber, rather it just returns the new state of the mount (LiveFiber | null), so it can work for all 3 mounting types. Once a fiber mount has been updated, it's queued to be rendered with flushMount.
If updateMount returns false, the update was a no-op because fiber arguments were identical (pointer equality). The update will be skipped and the mount not flushed. This follows the same implicit memoization rule that React has. It tends to trigger when a stateful component re-renders an old props.children.
A subtle point here is that fibers have no links/pointers pointing back to their parent. This is part practical, part ideological. It's practical because it cuts down on cyclic references to complicate garbage collection. It's ideological because it helps ensures one-way data flow.
There is also no global collection of fibers, except in the inspector. Like in an effect system, the job of determining what happens is entirely the result of an ongoing computation on JSX, i.e. something passed around like pure, immutable data. The tree determines its own shape as it's evaluated.
Queue and Path
Live needs to process fibers in tree order, i.e. as in a typical tree list view.
To do so, fibers are compared as values with compareFibers(a, b). This is based on references that are assigned only at fiber creation.
It has a path from the root of the tree to the fiber (at depth depth), containing the indices or keys.
{
// ...
depth: number,
path: Key[],
keys: (
number |
Map<Key, number>
)[],
}
A continuation next is ordered after the mount or mounts. This allows data fences to work naturally: the run-time only ensures all preceding fibers have been run first. For this, I insert an extra index into the path, 0 or 1, to distinguish the two sub-trees.
If many fibers have a static mount (i.e. always 1 child), this would create paths with lots of useless zeroes. To avoid this, a single mount has the same path as its parent, only its depth is increased. Paths can still be compared element-wise, with depth as the tie breaker. This easily reduces typical path length by 70%.
This is enough for children without keys, which are spawned statically. Their order in the tree never changes after creation, they can only be updated in-place or unmounted.
But for children with a key, the expectation is that they persist even if their order changes. Their keys are just unsorted ids, and their order is stored in the fiber.order and fiber.lookup of the parent in question.
This is referenced in the fiber.keys array. It's a flattened list of pairs [i, fiber.lookup], meaning the key at index i in the path should be compared using fiber.lookup. To keep these keys references intact, fiber.lookup is mutable and always modified in-place when reconciling.
Memoization
If a Component function is wrapped in memo(...), it won't be re-rendered if its individual props haven't changed (pointer equality). This goes deeper than the run-time's own oldArgs !== newArgs check.
{
// ...
version?: number,
memo?: number,
runs?: number,
}
For this, memoized fibers keep a version around. They also store a memo which holds the last rendered version, and a run count runs for debugging:
The version is used as one of the memo dependencies, along with the names and values of the props. Hence a memo(...) cache can be busted just by incrementing fiber.version, even if the props didn't change. Versions roll over at 32-bit.
To actually do the memoization, it would be nice if you could just wrap the whole component in useMemo. It doesn't work in the React model because you can't call other hooks inside hooks. So I've brought back the mythical useYolo... An earlier incarnation of this allowed fiber.state scopes to be nested, but lacked a good purpose. The new useYolo is instead a useMemo you can nest. It effectively hot swaps the entire fiber.state array with a new one kept in one of the slots:

This is then the first hook inside fiber.state. If the memo succeeds, the yolo'd state is preserved without treating it as an early return. Otherwise the component runs normally. Yolo'ing as the first hook has a dedicated fast path but is otherwise a perfectly normal hook.
The purpose of fiber.memo is so the run-time can tell whether it rendered the same thing as before, and stop. It can just compare the two versions, leaving the specifics of memoization entirely up to the fiber component itself. For example, to handle a custom arePropsEqual function in memo(…).
I always use version numbers as opposed to isDirty flags, because it leaves a paper trail. This provides the same ergonomics for mutable data as for immutable data: you can store a reference to a previous value, and do an O(1) equality check to know whether it changed since you last accessed it.
Whenever you have a handle which you can't look inside, such as a pointer to GPU memory, it's especially useful to keep a version number on it, which you bump every time you write to it. It makes debugging so much easier.
Inlining
Built-in operators are resolved with a hand-coded routine post-render, rather than being "normal" components. Their component functions are just empty and there is a big dispatch with if statements. Each is tagged with a isLiveBuiltin: true.
If a built-in operator is an only child, it's usually resolved inline. No new mount is created, it's immediately applied as part of updating the parent fiber. The glue in between tends to be "kernel land"-style code anyway, it doesn't need a whole new fiber, and it's not implemented in terms of hooks. The only fiber state it has is the type (i.e. function) of the last rendered JSX.
There are several cases where it cannot inline, such as rendering one built-in inside another built-in, or rendering a built-in as part of an array. So each built-in can always be mounted independently if needed.
From an architectural point of view, inlining is just incidental complexity, but this significantly reduces fiber overhead and keeps the user-facing component tree much tidier. It introduces a few minor problems around cleanup, but those are caught and handled.
Live also has a morph operator. This lets you replace a mount with another component, without discarding any matching children or their state. The mount's own state is still discarded, but its f, args, bound and type are modified in-place. A normal render follows, which will reconcile the children.
This is implemented in morphFiberCall. It only works for plain vanilla components, not other built-ins. The reason to re-use the fiber rather than transplant the children is so that references in children remain unchanged, without having to rekey them.
In Live, I never do a full recursive traversal of any sub-tree, unless that traversal is incremental and memoized. This is a core property of the system. Deep recursion should happen in user-land.
Environment
Fibers have access to a shared environment, provided by their parent. This is created in user-land through built-in ops and accessed via hooks.
- Context and captures
- Gathers and yeets
- Fences and suspend
- Quotes and reconcilers
- Unquote + quote
Context and captures
Live extends the classic React context:
{
// ...
context: {
values: Map<LiveContext | LiveCapture, Ref<any>>,
roots: Map<LiveContext | LiveCapture, number | LiveFiber>,
},
}
A LiveContext provides 1 value to N fibers. A LiveCapture collects N values into 1 fiber. Each is just an object created in user-land with makeContext / makeCapture, acting as a unique key. It can also hold a default value for a context.
The values map holds the current value of each context/capture. This is boxed inside a Ref as {current: value} so that nested sub-environments share values for inherited contexts.
The roots map points to the root fibers providing or capturing. This is used to allow useContext and useCapture to set up the right data dependency just-in-time. For a context, this points upstream in the tree, so to avoid a reverse reference, it's a number. For a capture, this points to a downstream continuation, i.e. the next of an ancestor, and can be a LiveFiber.
Normally children just share their parent's context. It's only when you <Provide> or <Capture> that Live builds a new, immutable copy of values and roots with a new context/capture added. Each context and capture persists for the lifetime of its sub-tree.
Captures build up a map incrementally inside the Ref while children are rendered, keyed by fiber. This is received in tree order after sorting:
<Capture
context={...}
children={...}
then={(values: T[]) => {
...
}}
/>
You can also just write capture(context, children, then), FYI.
This is an await or yield in disguise, where the then closure is spiritually part of the originating component function. Therefor it doesn't need to be memoized. The state of the next fiber is preserved even if you pass a new function instance every time.
Unlike React-style render props, then props can use hooks, because they run on an independent next fiber called Resume(…). This fiber will be re-run when values changes, and can do so without re-running Capture itself.
A then prop can render new elements, building a chain of next fibers. This acts like a rewindable generator, where each Resume provides a place where the code can be re-entered, without having to explicitly rewind any state. This requires the data passed into each closure to be immutable.
The logic for providing or capturing is in provideFiber(fiber, ...) and captureFiber(fiber, ...). Unlike other built-ins, these are always mounted separately and are called at the start of a new fiber, not the end of previous one. Their children are then immediately reconciled by inlineFiberCall(fiber, calls).
Gathers and yeets
Live offers a true return, in the form of yeet(value) (aka <Yeet>{value}</Yeet>). This passes a value back to a parent.
These values are gathered in an incremental map-reduce along the tree, to a root that mounted a gathering operation. It's similar to a Capture, except it visits every parent along the way. It's the complement to tree expansion during rendering.
This works for any mapper and reducer function via <MapReduce>. There is also an optimized code path for a simple array flatMap <Gather>, as well as struct-of-arrays flatMap <MultiGather>. It works just like a capture:
<Gather
children={...}
then={(
value: T[]
) => {
...
}}
/>
<MultiGather
children={...}
then={(
value: Record<string, T[]>
) => {
...
}}
/>
Each fiber in a reduction has a fiber.yeeted structure, created at mount time. Like a context, this relation never changes for the lifetime of the component.
It acts as a persistent cache for a yeeted value of type A and its map-reduction reduced of type B:
{
yeeted: {
// Same as fiber (for inspecting)
id: number,
// Reduction cache at this fiber
value?: A,
reduced?: B,
// Parent yeet cache
parent?: FiberYeet<A, B>,
// Reduction root
root: LiveFiber,
// ...
},
}
The last value yeeted by the fiber is kept so that all yeets are auto-memoized.
Each yeeted points to a parent. This is not the parent fiber but its fiber.yeeted. This is the parent reduction, which is downstream in terms of data dependency, not upstream. This forms a mirrored copy of the fiber tree and respects one-way data flow:
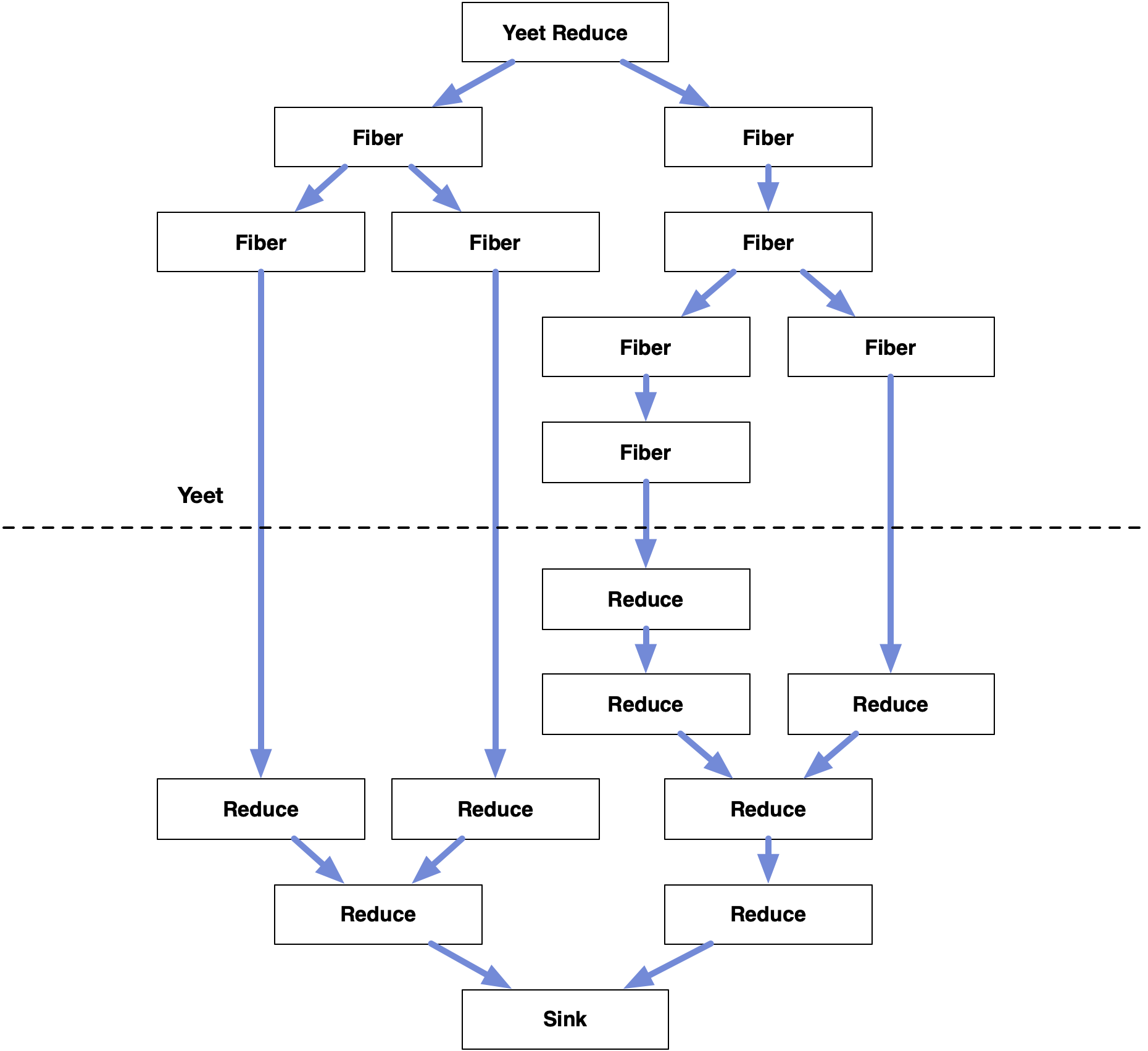
Again the linked root fiber (sink) is not an ancestor, but the next of an ancestor, created to receive the final reduced value.
If the reduced value is undefined, this signifies an empty cache. When a value is yeeted, parent caches are busted recursively towards the root, until an undefined is encountered. If a fiber mounts or unmounts children, it busts its reduction as well.
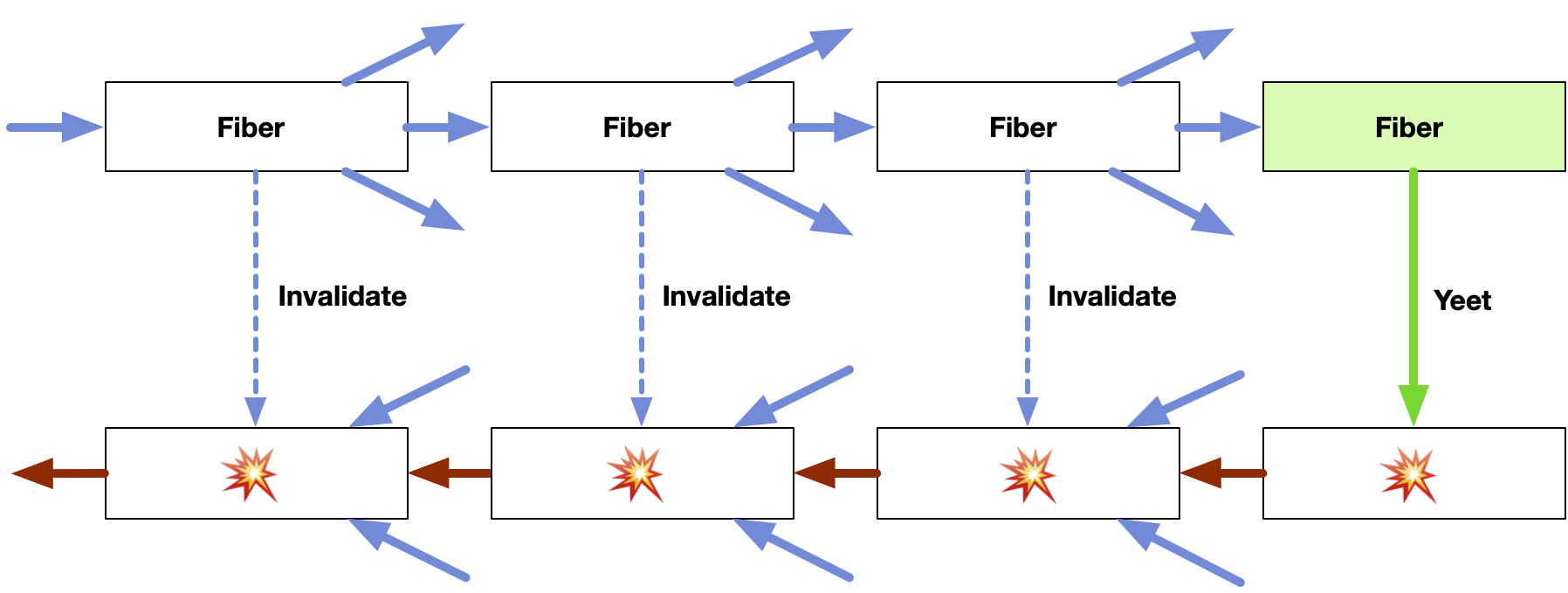
Fibers that yeet a value cannot also have children. This isn't a limitation because you can render a yeet beside other children, as just another mount, without changing the semantics. You can also render multiple yeets, but it's faster to just yeet a single list.
If you yeet undefined, this acts as a zero-cost signal: it does not affect the reduced values, but it will cause the reducing root fiber to be re-invoked. This is a tiny concession to imperative semantics, wildly useful.
This may seem very impure, but actually it's the opposite. With clean, functional data types, there is usually a "no-op" value that you could yeet: an empty array or dictionary, an empty function, and so on. You can always force-refresh a reduction without meaningfully changing the output, but it causes a lot of pointless cache invalidation in the process. Zero-cost signals are just an optimization.
When reducing a fiber that has a gathering next, it takes precedence over the fiber's own reduction: this is so that you can gather and reyeet in series, with the final reduction returned.
Fences and suspend
The specifics of a gathering operation are hidden behind a persistent emit and gather callback, derived from a classic map and reduce:
{
yeeted: {
// ...
// Emit a value A yeeted from fiber
emit: (fiber: LiveFiber, value: A) => void,
// Gather a reduction B from fiber
gather: (fiber: LiveFiber, self: boolean) => B,
// Enclosing yeet scope
scope?: FiberYeet<any, any>,
},
}
Gathering is done by the root reduction fiber, so gather is not strictly needed here. It's only exposed so you can mount a <Fence> inside an existing reduction, without knowing its specifics. A fence will grab the intermediate reduction value at that point in the tree and pass it to user-land. It can then be reyeeted.
One such use is to mimic React Suspense using a special toxic SUSPEND symbol. It acts like a NaN, poisoning any reduction it's a part of. You can then fence off a sub-tree to contain the spill and substitute it with its previous value or a fallback.
In practice, gather will delegate to one of gatherFiberValues, multiGatherFiberValues or mapReduceFiberValues. Each will traverse the sub-tree, reuse any existing reduced values (stopping the recursion early), and fill in any undefineds via recursion. Their code is kinda gnarly, given that it's just map-reduce, but that's because they're hand-rolled to avoid useless allocations.
The self argument to gather is such an optimization, only true for the final user-visible reduction. This lets intermediate reductions be type unsafe, e.g. to avoid creating pointless 1 element arrays.
At a gathering root, the enclosing yeet scope is also kept. This is to cleanly unmount an inlined gather, by restoring the parent's yeeted.
Quotes and reconcilers
Live has a reconciler in reconcileFiberCalls, but it can also mount <Reconciler> as an effect via mountFiberReconciler.
This is best understood by pretending this is React DOM. When you render a React tree which mixes <Components> with <html>, React reconciles it, and extracts the HTML parts into a new tree:
<App> <div>
<Layout> => <div>
<div> <span>
<div> <img>
<Header>
<span>
<Logo>
<img>
Each HTML element is implicitly quoted inside React. They're only "activated" when they become real on the right. The ones on the left are only stand-ins.
That's also what a Live <Reconcile> does. It mounts a normal tree of children, but it simultaneously mounts an independent second tree, under its next mount.
If you render this:
<App>
<Reconcile>
<Layout>
<Quote>
<Div>
<Div>
<Unquote>
<Header>
<Quote>
<Span>
<Unquote>
<Logo>
<Quote>
<Img />
...
You will get:
It adds a quote environment to the fiber:
{
// ...
quote: {
// Reconciler fiber
root: number,
// Fiber in current sub-tree
from: number,
// Fiber in other sub-tree
to: LiveFiber,
// Enclosing reconciler scope
scope?: FiberQuote,
}
}
When you render a <Quote>...</Quote>, whatever's inside ends up mounted on the to fiber.
Quoted fibers will have a similar fiber.unquote environment. If they render an <Unquote>...</Unquote>, the children are mounted back on the quoting fiber.
Each time, the quoting or unquoting fiber becomes the new to fiber on the other side.
The idea is that you can use this to embed one set of components inside another as a DSL, and have the run-time sort them out.
This all happens in mountFiberQuote(…) and mountFiberUnquote(…). It uses reconcileFiberCall(…) (singular). This is an incremental version of reconcileFiberCalls(…) (plural) which only does one mount/unmount at a time. The fiber id of the quote or unquote is used as the key of the quoted or unquoted fiber.
const Queue = ({children}) => (
reconcile(
quote(
gather(
unquote(children),
(v: any[]) =>
<Render values={v} />
))));
The quote and unquote environments are separate so that reconcilers can be nested: at any given place, you can unquote 'up' or quote 'down'. Because you can put multiple <Unquote>s inside one <Quote>, it can also fork. The internal non-JSX dialect is very Lisp-esque, you can rap together some pretty neat structures with this.
Because quote are mounted and unmounted incrementally, there is a data fence Reconcile(…) after each (un)quote. This is where the final set is re-ordered if needed.
The data structure actually violates my own rule about no-reverse links. After you <Quote>, the fibers in the second tree have a link to the quoting fiber which spawned them. And the same applies in the other direction after you <Unquote>.
The excuse is ergonomics. I could break the dependency by creating a separate sub-fiber of <Quote> to serve as the unquoting point, and vice versa. But this would bloat both trees with extra fibers, just for purity's sake. It already has unavoidable extra data fences, so this matters.
At a reconciling root, the enclosing quote scope is added to fiber.quote, just like in yeeted, again for clean unmounting of inlined reconcilers.
Unquote-quote
There is an important caveat here. There are two ways you could implement this.
One way is that <Quote>...</Quote> is a Very Special built-in, which does something unusual: it would traverse the children tree it was given, and go look for <Unquote>...</Unquote>s inside. It would have to do so recursively, to partition the quoted and unquoted JSX. Then it would have to graft the quoted JSX to a previous quote, while grafting the unquoted parts to itself as mounts. This is the React DOM mechanism, obfuscated. This is also how quoting works in Lisp: it switches between evaluation mode and AST mode.
I have two objections. The first is that this goes against the whole idea of evaluating one component incrementally at a time. It wouldn't be working with one set of mounts on a local fiber: it would be building up args inside one big nested JSX expression. JSX is not supposed to be a mutable data structure, you're supposed to construct it immutably from the inside out, not from the outside in.
The second is that this would only work for 'balanced' <Quote>...<Unquote>... pairs appearing in the same JSX expression. If you render:
<Present>
<Slide />
</Present>
...then you couldn't have <Present> render a <Quote> and <Slide> render an <Unquote> and have it work. It wouldn't be composable as two separate portals.
The only way for the quotes/unquotes to be revealed in such a scenario is to actually render the components. This means you have to actively run the second tree as it's being reconciled, same as the first. There is no separate update + commit like in React DOM.
This might seem pointless, because all this does is thread the data flow into a zigzag between the two trees, knitting the quote/unquote points together. The render order is the same as if <Quote> and <Unquote> weren't there. The path and depth of quoted fibers reveals this, which is needed to re-render them in the right order later.
The key difference is that for all other purposes, those fibers do live in that spot. Each tree has its own stack of nested contexts. Reductions operate on the two separate trees, producing two different, independent values. This is just "hygienic macros" in disguise, I think.
Use.GPU's presentation system uses a reconciler to wrap the layout system, adding slide transforms and a custom compositor. This is sandwiched in-between it and the normal renderer.
A plain declarative tree of markup can be expanded into:
<Device>
<View>
<Present>
<Slide>
<Object />
<Object />
</Slide>
<Slide>
<Object />
<Object />
</Slide>
</Present>
</View>
</Device>
I also use a reconciler to produce the WebGPU command queue. This is shared for an entire app and sits at the top. The second tree just contains quoted yeets. I use zero-cost signals here too, to let data sources signal that their contents have changed. There is a short-hand <Signal /> for <Quote><Yeet /></Quote>.
Note that you cannot connect the reduction of tree 1 to the root of tree 2: <Reconcile> does not have a then prop. It doesn't make sense because the next fiber gets its children from elsewhere, and it would create a rendering cycle if you tried anyway.
If you need to spawn a whole second tree based on a first, that's what a normal gather already does. You can use it to e.g. gather lambdas that return memoized JSX. This effectively acts as a two-phase commit.
The Use.GPU layout system does this repeatedly, with several trees + gathers in a row. It involves constraints both from the inside out and the outside in, so you need both tree directions. The output is UI shapes, which need to be batched together for efficiency and turned into a data-driven draw call.
The Run-Time
With all the pieces laid out, I can now connect it all together.
Before render(<App />) can render the first fiber, it initializes a very minimal run-time. So this section will be kinda dry.
This is accessed through fiber.host and exposes a handful of APIs:
- a queue of pending state changes
- a priority queue for traversal
- a fiber-to-fiber dependency tracker
- a resource disposal tracker
- a stack slicer for reasons
State changes
When a setState is called, the state change is added to a simple queue as a lambda. This allows simultaneous state changes to be batched together. For this, the host exposes a schedule and a flush method.
{
// ...
host: {
schedule: (fiber: LiveFiber, task?: () => boolean | void) => void,
flush: () => void,
// ...
}
This comes from makeActionScheduler(…). It wraps a native scheduling function (e.g. queueMicrotask) and an onFlush callback:
const makeActionScheduler = (
schedule: (flush: ArrowFunction) => void,
onFlush: (fibers: LiveFiber[]) => void,
) => {
// ...
return {schedule, flush};
}
The callback is set up by render(…). It will take the affected fibers and call renderFibers(…) (plural) on them.
The returned schedule(…) will trigger a flush, so flush() is only called directly for sync execution, to stay within the same render cycle.
Traversal
The host keeps a priority queue (makePriorityQueue) of pending fibers to render, in tree order:
{
// ...
host: {
// ...
visit: (fiber: LiveFiber) => void,
unvisit: (fiber: LiveFiber) => void,
pop: () => LiveFiber | null,
peek: () => LiveFiber | null,
}
}
renderFibers(…) first adds the fibers to the queue by calling host.visit(fiber).
A loop in renderFibers(…) will then call host.peek() and host.pop() until the queue is empty. It will call renderFiber(…) and updateFiber(…) on each, which will call host.unvisit(fiber) in the process. This may also cause other fibers to be added to the queue.
The priority queue is a singly linked list of fibers. It allows fast appends at the start or end. To speed up insertions in the middle, it remembers the last inserted fiber. This massively speeds up the very common case where multiple fibers are inserted into an existing queue in tree order. Otherwise it just does a linear scan.
It also has a set of all the fibers in the queue, so it can quickly do presence checks. This means visit and unvisit can safely be called blindly, which happens a lot.
// Re-insert all fibers that descend from fiber
const reorder = (fiber: LiveFiber) => {
const {path} = fiber;
const list: LiveFiber[] = [];
let q = queue;
let qp = null;
while (q) {
if (compareFibers(fiber, q.fiber) >= 0) {
hint = qp = q;
q = q.next;
continue;
}
if (isSubNode(fiber, q.fiber)) {
list.push(q.fiber);
if (qp) {
qp.next = q.next;
q = q.next;
}
else {
pop();
q = q.next;
}
}
break;
}
if (list.length) {
list.sort(compareFibers);
list.forEach(insert);
}
};There is an edge case here though. If a fiber re-orders its keyed children, the compareFibers fiber order of those children changes. But, because of long-range dependencies, it's possible for those children to already be queued. This might mean a later cousin node could render before an earlier one, though never a child before a parent or ancestor.
In principle this is not an issue because the output—the reductions being gathered—will be re-reduced in new order at a fence. From a pure data-flow perspective, this is fine: it would even be inevitable in a multi-threaded version. In practice, it feels off if code runs out of order for no reason, especially in a dev environment.
So I added optional queue re-ordering, on by default. This can be done pretty easily because the affected fibers can be found by comparing paths, and still form a single group inside the otherwise ordered queue: scan until you find a fiber underneath the parent, then pop off fibers until you exit the subtree. Then just reinsert them.
This really reminds me of shader warp reordering in raytracing GPUs btw.
Dependencies
To support contexts and captures, the host has a long-range dependency tracker (makeDependencyTracker):
{
host: {
// ...
depend: (fiber: LiveFiber, root: number) => boolean,
undepend: (fiber: LiveFiber, root: number) => void,
traceDown: (fiber: LiveFiber) => LiveFiber[],
traceUp: (fiber: LiveFiber) => number[],
}
};
It holds two maps internally, each mapping fibers to fibers, for precedents and descendants respectively. These are mapped as LiveFiber -> id and id -> LiveFiber, once again following the one-way rule. i.e. It gives you real fibers if you traceDown, but only fiber IDs if you traceUp. The latter is only used for highlighting in the inspector.
The depend and undepend methods are called by useContext and useCapture to set up a dependency this way. When a fiber is rendered (and did not memoize), bustFiberDeps(…) is called. This will invoke traceDown(…) and call host.visit(…) on each dependent fiber. It will also call bustFiberMemo(…) to bump their fiber.version (if present).
Yeets could be tracked the same way, but this is unnecessary because yeeted already references the root statically. It's a different kind of cache being busted too (yeeted.reduced) and you need to bust all intermediate reductions along the way. So there is a dedicated visitYeetRoot(…) and bustFiberYeet(…) instead.
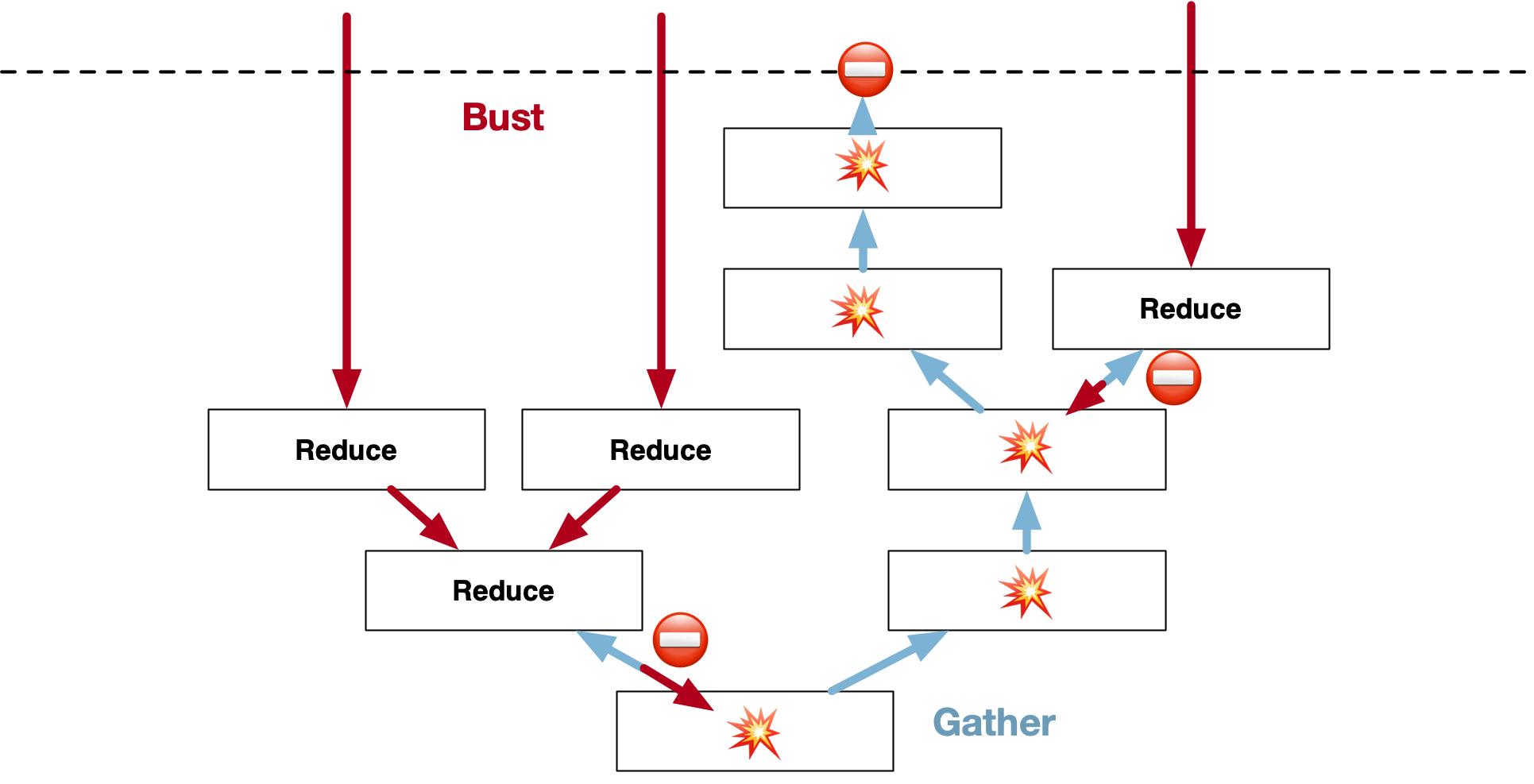
Yeets are actually quite tricky to manage because there are two directions of traversal here. A yeet must bust all the caches towards the root. Once those caches are busted, another yeet shouldn't traverse them again until filled back in. It stops when it encounters undefined. Second, when the root gathers up the reduced values from the other end, it should be able to safely accept any defined yeeted.reduced as being correctly cached, and stop as well.
The invariant to be maintained is that a trail of yeeted.reduced === undefined should always lead all the way back to the root. New fibers have an undefined reduction, and old fibers may be unmounted, so these operations also bust caches. But if there is no change in yeets, you don't need to reduce again. So visitYeetRoot is not actually called until and unless a new yeet is rendered or an old yeet is removed.
Managing the lifecycle of this is simple, because there is only one place that triggers a re-reduction to fill it back in: the yeet root. Which is behind a data fence. It will always be called after the last cache has been busted, but before any other code that might need it. It's impossible to squeeze anything in between.
It took a while to learn to lean into this style of thinking. Cache invalidation becomes a lot easier when you can partition your program into "before cache" and "after cache". Compared to the earliest versions of Live, the how and why of busting caches is now all very sensible. You use immutable data, or you pass a mutable ref and a signal. It always works.
Resources
The useResource hook lets a user register a disposal function for later. useContext and useCapture also need to dispose of their dependency when unmounted. For this, there is a disposal tracker (makeDisposalTracker) which effectively acts as an onFiberDispose event listener:
{
host: {
// ...
// Add/remove listener
track: (fiber: LiveFiber, task: Task) => void,
untrack: (fiber: LiveFiber, task: Task) => void,
// Trigger listener
dispose: (fiber: LiveFiber) => void,
}
}
Disposal tasks are triggered by host.dispose(fiber), which is called by disposeFiber(fiber). The latter will also set fiber.bound to undefined so the fiber can no longer be called.
A useResource may change during a fiber's lifetime. Rather than repeatedly untrack/track a new disposal function each time, I store a persistent resource tag in the hook state. This holds a reference to the latest disposal function. Old resources are explicitly disposed of before new ones are created, ensuring there is no overlap.
Stack Slicing
A React-like is a recursive tree evaluator. A naive implementation would use function recursion directly, using the native CPU stack. This is what Live 0.0.1 did. But the run-time has overhead, with its own function calls sandwiched in between (e.g. updateFiber, reconcileFiberCalls, flushMount). This creates towering stacks. It also cannot be time-sliced, because all the state is on the stack.
In React this is instead implemented with a flat work queue, so it only calls into one component at a time. A profiler shows it repeatedly calling performUnitOfWork, beginWork, completeWork in a clean, shallow trace.

Live could do the same with its fiber priority queue. But the rendering order is always just tree order. It's only interrupted and truncated by memoization. So the vast majority of the time you are adding a fiber to the front of the queue only to immediately pop it off again.
The queue is a linked list so it creates allocation overhead. This massively complicates what should just be a native function call.
Live says "¿Por qué no los dos?" and instead has a stack slicing mechanism (makeStackSlicer). It will use the stack, but stop recursion after N levels, where N is a global knob that current sits at 20. The left-overs are enqueued.
This way, mainly fibers pinged by state changes and long-range dependency end up in the queue. This includes fenced continuations, which must always be called indirectly. If a fiber is in the queue, but ends up being rendered in a parent's recursion, it's immediately removed.
{
host: {
// ...
depth: (depth: number) => void,
slice: (depth: number) => boolean,
},
}
When renderFibers gets a fiber from the queue, it calls host.depth(fiber.depth) to calibrate the slicer. Every time a mount is flushed, it will then call host.slice(mount.depth) to check if it should be sliced off. If so, it calls host.visit(…) to add it to the queue, but otherwise it just calls renderFiber / updateFiber directly. The exception is when there is a data fence, when the queue is always used.
Here too there is a strict mode, on by default, which ensures that once the stack has been sliced, no further sync evaluation can take place higher up the stack.
One-phase commit
Time to rewind.
A Live app consists of a tree of such fiber objects, all exactly the same shape, just with different state and environments inside. It's rendered in a purely one-way data flow, with only a minor asterisk on that statement.
The host is the only thing coordinating, because it's the only thing that closes the cycle when state changes. This triggers an ongoing traversal, during which it only tells fibers which dependencies to ping when they render. Everything else emerges from the composition of components.
Hopefully you can appreciate that Live is not actually Cowboy React, but something else and deliberate. It has its own invariants it's enforcing, and its own guarantees you can rely on. Like React, it has a strict and a non-strict mode that is meaningfully different, though the strictness is not about it nagging you, but about how anally the run-time will reproduce your exact declared intent.
It does not offer any way to roll back partial state changes once made, unlike React. This idempotency model of rendering is good when you need to accommodate mutable references in a reactive system. Immediate mode APIs tend to use these, and Live is designed to be plugged in to those.
The nice thing about Live is that it's often meaningful to suspend a partially rendered sub-tree without rewinding it back to the old state, because its state doesn't represent anything directly, like HTML does. It's merely reduced into a value, and you can simply re-use the old value until it has unsuspended. There is no need to hold on to all the old state of the components that produced it. If the value being gathered is made of lambdas, you have your two phases: the commit consists of calling them once you have a full set.
In Use.GPU, you work with memory on the GPU, which you allocate once and then reuse by reference. The entire idea is that the view can re-render without re-rendering all components that produced it, the same way that a browser can re-render a page by animating only the CSS transforms. So I have to be all-in on mutability there, because updated transforms have to travel through the layout system without re-triggering it.
I also use immediate mode for the CPU-side interactions, because I've found it makes UI controllers 2-3x less complicated. One interesting aspect here is that the difference between capturing and bubbling events, i.e. outside-in or inside-out, is just before-fence and after-fence.
Live is also not a React alternative: it plays very nicely with React. You can nest one inside the other and barely notice. The Live inspector is written in React, because I needed it to work even if Live was broken. It can memoize effectively in React because Live is memoized. Therefor everything it shows you is live, including any state you open up.
The inspector is functionality-first so I throw purity out the window and just focus on UX and performance. It installs a host.__ping callback so it can receive fiber pings from the run-time whenever they re-render. The run-time calls this via pingFiber in the right spots. Individual fibers can make themselves inspectable by adding undocumented/private props to fiber.__inspect. There are some helper hooks to make this prettier but that's all. You can make any component inspector-highlightable by having it re-render itself when highlighted.
* * *
Writing this post was a fun endeavour, prompting me to reconsider some assumptions from early on. I also fixed a few things that just sounded bad when said out loud. You know how it is.
I removed some lingering unnecessary reverse fiber references. I was aware they weren't load bearing, but that's still different from not having them at all. The only one I haven't mentioned is the capture keys, which are a fiber so that they can be directly compared. In theory it only needs the id, path, depth, keys, and I could package those up separately, but it would just create extra objects, so the jury allows it.
Live can model programs shaped like a one-way data flow, and generates one-way data itself. There are some interesting correspondences here.
- Live keep state entirely in
fiberobjects, while fibers run entirely onfiber.state. Afiberobject is just a fixed dictionary of properties, always the same shape, just likefiber.stateis for a component's lifetime. - Children arrays without keys must be fixed-length and fixed-order (a fragment), but may have
nulls. This is very similar to how no-hooks will skip over a missing spot in thefiber.statearray and zero out the hook, so as to preserve hook order. - Live hot-swaps a global
currentFiberpointer to switch fibers, anduseYolohot-swaps a fiber's own localstateto switch hook scopes. - Memoizing a component can be implemented as a nested
useMemo. Bumping the fiber version is really a bespokesetStatewhich is resolved during next render.
The lines between fiber, fiber.state and fiber.mounts are actually pretty damn blurry.
A lot of mechanisms appear twice, once in a non-incremental form and once in an incremental form. Iteration turns into mounting, sequences turn into fences, and objects get chopped up into fine bits of cached state, either counted or with keys. The difference between hooks and a gather of unkeyed components gets muddy. It's about eagerness and dependency.
If Live is react-react, then a self-hosted live-live is hiding in there somewhere. Create a root fiber, give it empty state, off you go. Inlining would be a lot harder though, and you wouldn't be able to hand-roll fast paths as easily, which is always the problem in FP. For a JS implementation it would be very dumb, especially when you know that the JS VM already manages object prototypes incrementally, mounting one prop at a time.
I do like the sound of an incremental Lisp where everything is made out of flat state lists instead of endless pointer chasing. If it had the same structure as Live, it might only have one genuine linked list driving it all: the priority queue, which holds elements pointing to elements. The rest would be elements pointing to linear arrays, a data structure that silicon caches love. A data-oriented Lisp maybe? You could even call it an incremental GPU. Worth pondering.
What Live could really use is a WASM pony with better stack access and threading. But in the mean time, it already works.
The source code for the embedded examples can be found on GitLab.
If your browser can do WebGPU (desktop only for now), you can load up any of the Use.GPU examples and inspect them.