
On Variance and Extensibility

Making code reusable is not an art, it's a job
Extensibility of software is a weird phenomenon, very poorly understood in the software industry. This might seem strange to say, as you are reading this in a web browser, on an operating system, desktop or mobile. They are by all accounts, quite extensible and built out of reusable, shared components, right?
But all these areas are suffering enormous stagnation. Microsoft threw in the towel on browsers. Mozilla fired its engineers. Operating systems have largely calcified around a decades-old feature set, and are just putting up fortifications. The last big shift here was Apple's version of the mobile web and app store, which ended browser plug-ins like Flash or Java in one stroke.
Most users are now silo'd inside an officially approved feature set. Except for Linux, which is still figuring out how audio should work. To be fair, so is the web. There's WebAssembly on the horizon, but the main thing it will have access to is a creaky DOM and an assortment of poorly conceived I/O APIs.
It sure seems like the plan was to have software work much like interchangeable legos. Only it didn't happen at all, not as far as end-users are concerned. Worse, the HTTP-ificiation of everything has largely killed off the cow paths we used to have. Data sits locked behind proprietary APIs. Interchange doesn't really happen unless there is a business case for it. The default of open has been replaced with a default of closed.
This death of widespread extensibility ought to seem profoundly weird, or at least, ungrappled with.
We used to collect file types like Pokémon. What happened? If you dig into this, you work your way through types, but then things quickly get existential: how can a piece of code do anything useful with data it does not understand? And if two programs can interpret and process the same data the same way, aren't they just the same code written twice?
Most importantly: does this actually tell us anything useful about how to design software?

The Birds of America, John James Audubon (1827)
Well?
Let's start with a simpler question.
If I want a system to be extensible, I want to replace a part with something more specialized, more suitable to my needs. This should happen via the substitution principle: if it looks like a duck, walks like a duck and quacks like a duck, it's a duck, no matter which kind. You can have any number of sub-species of ducks, and they can do things together, including making weird new little ducks.
So, consider:
If I have a valid piece of code that uses the type Animal, I should be able to replace Animal with the subtype Duck, Pig or Cow and still have valid code.
True or False? I suspect your answer will depend on whether you've mainly written in an object-oriented or functional style. It may seem entirely obvious, or not at all.
This analogy by farm is the usual intro to inheritance: Animal is the supertype. When we call .say(), the duck quacks, but the cow moos. The details are abstracted away and encapsulated. Easy. We teach inheritance and interfaces this way to novices, because knowing what sounds your objects make is very important in day-to-day coding.
But, seriously, this obscures a pretty important distinction. Understanding it is crucial to making extensible software. Because the statement is False.
So, the farmer goes to feed the animals:
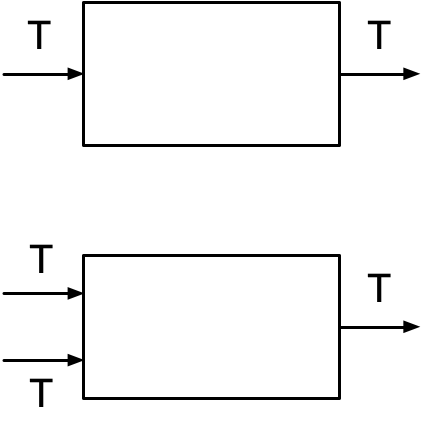
type GetAnimal = () => Animal;
type FeedAnimal = (animal: Animal) => void;
How does substitution apply here? Well, it's fine to get ducks when you were expecting animals. Because anything you can do to an Animal should also work on a Duck. So the function () => Duck can stand-in for an () => Animal.
But what about the actions? If I want to feed the ducks breadcrumbs, I might use a function feedBread which is a Duck => void. But I can't feed that same bread to the cat and I cannot pass feedBread to the farmer who expects an Animal => void. He might try to call it on the wrong Animal.
This means the allowable substitution here is reversed depending on use:
- A function that provides a
Duckalso provides anAnimal. - A function that needs an
Animalwill also accept aDuck.
But it doesn't work in the other direction. It seems pretty obvious when you put it this way. In terms of types:
- Any function
() => Duckis a valid substitute for() => Animal. - Any function
Animal => voidis a valid substitute forDuck => void.
It's not about using a type T, it's about whether you are providing it or consuming it. The crucial distinction is whether it appears after or before the =>. This is why you can't always replace Animal with Duck in just any code.
This means that if you have a function of a type T => T, then T appears on both sides of =>, which means neither substitution is allowed. You cannot replace the function with an S => S made out of a subtype or supertype S, not in general. It would either fail on unexpected input, or produce unexpected output.
This shouldn't be remarkable at all among people who code in typed languages. It's only worth noting because intros to OO inheritance don't teach you this, suggesting the answer is True. We use the awkward words covariant and contravariant to describe the two directions, and remembering which is which is hard.
I find this quite strange. How is it people only notice one at first?
let duck: Duck = new Duck();
let animal: Animal = duck;
class Duck extends Animal {
method() {
// ...
}
}
Here's one explanation. First, you can think of ordinary values as being returned from an implicit getter () => value. This is your default mental model, even if you never really thought about it.
Second, it's OO's fault. When you override a method in a subclass, you are replacing a function (this: Animal, ...) => with a function (this: Duck, ...) => . According to the rules of variance, this is not allowed, because it's supposed to be the other way around. To call it on an Animal, you must invoke animal.say() via dynamic dispatch, which the language has built-in.
Every non-static method of class T will have this: T as a hidden argument, so this constrains the kinds of substitutions you're allowed to describe using class methods. Because when both kinds of variance collide, you are pinned at one level of abstraction and detail, because there, T must be invariant.
This is very important for understanding extensibility, because the common way to say "neither co- nor contravariant" is actually just "vendor lock-in".

The Mirage of Extensibility
The goal of extensibility is generally threefold:
- Read from arbitrary sources of data
- Perform arbitrary operations on that data
- Write to arbitrary sinks of data
Consider something like ImageMagick or ffmpeg. It operates on a very concrete data type: one or more images (± audio). These can be loaded and saved in a variety of different formats. You can apply arbitrary filters as a processing pipeline, configurable from the command line. These tools are swiss army knives which seem to offer real extensibility.
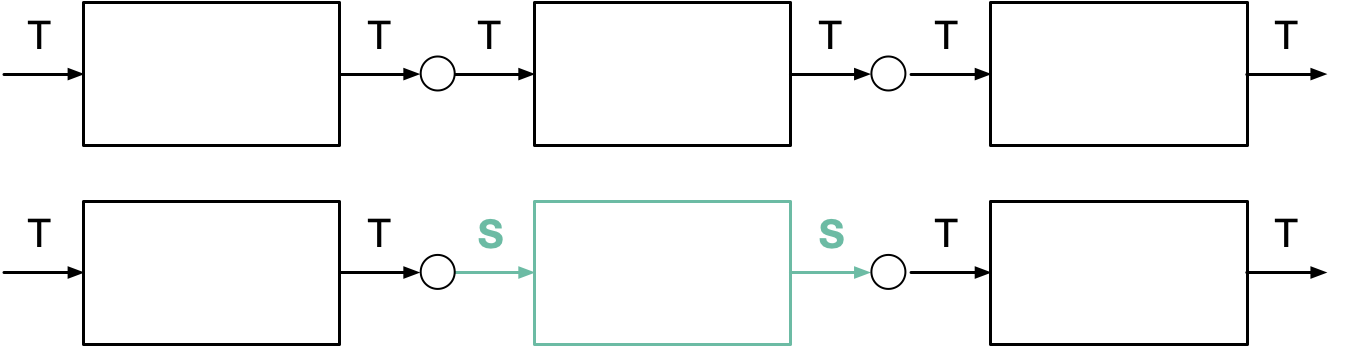
type Input<T> = () => T;
type Process<T> = T => T;
type Output<T> = T => void;
Formally, you decode your input into some shared representation T. This forms the glue between your processing blocks. Then it can be sent back to any output to be encoded.
It's crucial here that Process has the same input and output type, as it enables composition of operations like lego. If it was Process<A, B> instead, you would only be able to chain certain combinations (A → B, B → C, C → D, ...). We want to have a closed, universal system where any valid T produces a new valid T.
Of course you can also define operators like (T, T) => T. This leads to a closed algebra, where every op always works on any two Ts. For the sake of brevity, operators are implied below. In practice, most blocks are also configurable, which means it's an options => T => T.
This seems perfectly extensible, and a textbook model for all sorts of real systems. But is it really? Reality says otherwise, because it's engineering, not science.
Consider a PNG: it's not just an image, it's a series of data blocks which describe an image, color information, physical size, and so on. To faithfully read a PNG and write it out again requires you to understand and process the file at this level. Therefor any composition of a PNGInput with a PNGOutput where T is just pixels is insufficient: it would throw away all the metadata, producing an incomplete file.
Now add in JPEG: same kind of data, very different compression. There are also multiple competing metadata formats (JFIF, EXIF, ...). So reading and writing a JPEG faithfully requires you to understand a whole new data layout, and store multiple kinds of new fields.
This means a swiss-army-knife's T is really some kind of wrapper in practice. It holds both data and metadata. The expectation is that operations on T will preserve that metadata, so it can be reattached to the output. But how do you do that in practice? Only the actual raw image data is compatible between PNG and JPEG, yet you must be able to input and output either.
meta = {
png?: {...}
jpeg?: {...}
}
If you just keep the original metadata in a struct like this, then a Process<T> interested in metadata has to be aware of all the possible image formats that can be read, and try them all. This means it's not really extensible: adding a new format means updating all the affected Process blocks. Otherwise Input<T> and Process<T> don't compose in a useful sense.
meta = {
color: {...},
physical: {...},
geo: {...},
}
If you instead harmonize all the metadata into a single, unified schema, then this means new Input<T> and Output<T> blocks are limited to metadata that's already been anticipated. This is definitely not extensible, because you cannot support any new concepts faithfully.
If you rummage around inside ImageMagick you will in fact encounter this. PNG and JPEG's unique flags and quirks are natively supported.
meta = {
color: {...},
physical: {...},
geo: {...},
x-png?: {...}
x-jpeg?: {...}
}
One solution is to do both. You declare a standard schema upfront, with common conventions that can be relied on by anyone. But you also provide the ability to extend it with custom data, so that specific pairs of Input/Process/Output can coordinate. HTTP and e-mail headers are X-able.
meta = {
img?: {
physical?: {...},
color?: {...},
},
fmt?: {
png?: {...},
jfif?: {...},
exif?: {...},
},
},
The problem is that there is no universal reason why something should be standard or not. Standard is the common set of functionality "we" are aware of today. Non-standard is what's unanticipated. This is entirely haphazard. For example, instead of an x-jpeg, it's probably better to define an x-exif because Exif tags are themselves reusable things. But why stop there?
Mistakes stick and best practices change, so the only way to have a contingency plan in place is for it to already exist in the previous version. For example, through judicious use of granular, optional namespaces.
The purpose is to be able to make controlled changes later that won't mess with most people's stuff. Some breakage will still occur. The structure provides a shared convention for anticipated needs, paving the cow paths. Safe extension is the default, but if you do need to restructure, you have to pick a new namespace. Conversion is still an issue, but at least it is clearly legible and interpretable which parts of the schema are being used.
One of the smartest things you can do ahead of time is to not version your entire format as v1 or v2. Rather, remember the version for any namespace you're using, like a manifest. It allows you to define migration not as a transaction on an entire database or dataset at once, but rather as an idempotent process that can be interrupted and resumed. It also provides an opportunity to define a reverse migration that is practically reusable by other people.
This is how you do it if you plan ahead. So naturally this is not how most people do it.

N+1 Standards
X- fields and headers are the norm and have a habit of becoming defacto standards. When they do, you find it's too late to clean it up into a new standard. People try anyway, like with X-Forwarded-For vs Forwarded. Or -webkit-transform vs transform. New software must continue to accept old input. It must also produce output compatible with old software. This means old software never needs to be updated, which means new software can never ditch its legacy code.
Let's look at this story through a typed lens.
What happens is, someone turns an Animal => Animal into a Duck => Duck without telling anyone else, by adding an X- field. This is fine, because Animal ignores unknown metadata, and X- fields default to none. Hence every Animal really is a valid Duck, even though Duck specializes Animal.
Slowly more people replace their Animal => Animal type with Duck => Duck. Which means ducks are becoming the new defacto Animal. But then someone decides it needed to be a Chicken => Chicken instead, and that chickens are the new Animal. Not everyone is on-board with that.
So you need to continue to support the old Duck and the new Chicken on the input side. You also need to output something that passes as both Duck and Chicken, that is, a ChickenDuck. Your signature becomes:
(Duck | Chicken | ChickenDuck) => ChickenDuck
This is not what you wanted at all, because it always lays two eggs at the same time, one with an X and one without. This is also a metaphor for IPv4 vs IPv6.
If you have one standard, and you make a new standard, now you have 3 standards: the old one, the theoretical new one, and the actual new one.
Invariance pops up again. When you have a system built around signature T => T, you cannot simply slot in a S => S of a super or sub S. Most Input and Output in the wild still only produces and consumes T. You have to slot in an actual T => S somewhere, and figure out what S => T means.
Furthermore, for this to do something useful in a real pipeline, T already has to be able to carry all the information that S needs. And S => T cannot strip it out again. The key is to circumvent invariance: neither type is really a subtype or supertype of the other. They are just different views and interpretations of the same underlying data, which must already be extensible enough.
Backwards compatibility is then the art of changing a process Animal => Animal into a Duck => Duck while avoiding a debate about what specifically constitutes quacking. If you remove an X- prefix to make it "standard", this stops being true. The moment you have two different sources of the same information, now you have to decide whose job it is to resolve two into one, and one back into two.
This is particularly sensitive for X-Forwarded-For, because it literally means "the network metadata is wrong, the correct origin IP is ..." This must come from a trusted source like a reverse proxy. It's the last place you want to create compatibility concerns.

If you think about it, this means you can never be sure about any Animal either: how can you know there isn't an essential piece of hidden metadata traveling along that you are ignoring, which changes the meaning significantly?
Consider what happened when mobile phones started producing JPEGs with portrait vs landscape orientation metadata. Pictures were randomly sideways and upside down. You couldn't even rely on something as basic as the image width actually being, you know, the width. How many devs would anticipate that?
The only reason this wasn't a bigger problem is because for 99% of use-cases, you can just apply the rotation once upfront and then forget about it. That is, you can make a function RotatableImage => Image aka a Duck => Animal. This is an S => T that doesn't lose any information anyone cares about. This is the rare exception, only done occasionally, as a treat.
If you instead need to upgrade a whole image and display pipeline to support, say, high-dynamic range or P3 color, that's a different matter entirely. It will never truly be 100% done everywhere, we all know that. But should it be? It's another ChickenDuck scenario, because now some code wants images to stay simple, 8-bit and sRGB, while other code wants something else. Are you going to force each side to deal with the existence of the other, in every situation? Or will you keep the simplest case simple?
A plain old 2D array of pixels is not sufficient for T in the general case, but it is too useful on its own to simply throw it out. So you shouldn't make an AbstractImage which specializes into a SimpleImage and an HDRImage and a P3Image, because that means your SimpleImage isn't simple anymore. You should instead make an ImageView with metadata, which still contains a plain Image with only raw pixels. That is, a SimpleImage is just an ImageView<Image, NoColorProfile>. That way, there is still a regular Image on the inside. Code that provides or needs an Image does not need to change.
It's important to realize these are things you can only figure out if you have a solid idea of how people actually work with images in practice. Like knowing that we can just all agree to "bake in" a rotation instead of rewriting a lot of code. Architecting from the inside is not sufficient, you must position yourself as an external user of what you build, someone who also has a full-time job.
If you want a piece of software to be extensible, that means the software will become somebody else's development dependency. This puts huge constraints on its design and how it can change. You might say there is no such thing as an extensible schema, only an unfinished schema, because every new version is really a fork. But this doesn't quite capture it, and it's not quite so absolute in practice.
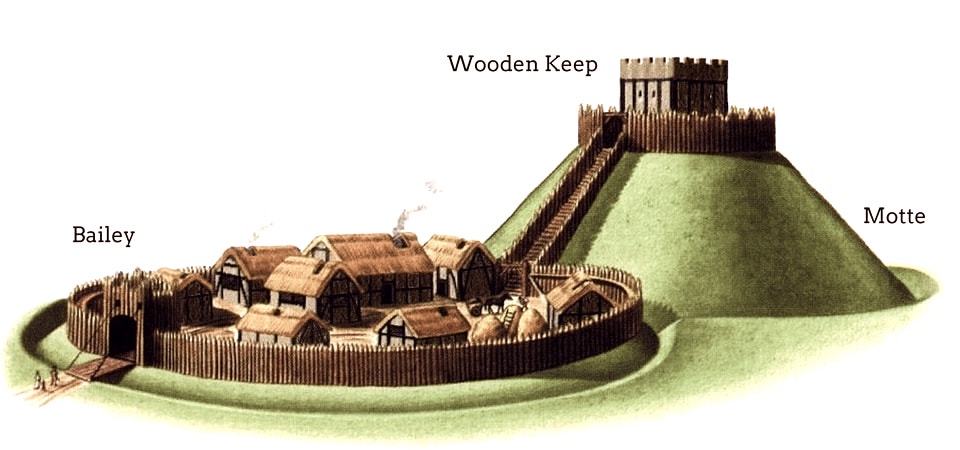
Colonel Problem
Interoperability is easy in pairs. You can model this as an Input<T> "A" connecting to an Output<T> "B". This does not need to cover every possible T, it can be a reduced subset R of T. For example, two apps exchange grayscale images (R) as color PNGs (T). Every R is also a T, but not every T is an R. This means:
- Any function
() => grayscaleImageis a valid substitute for() => colorImage. - Any function
(colorImage) => voidis a valid substitute for(grayscaleImage) => void.
This helps A, which is an => R pretending to be a => T. But B still needs to be an actual T =>, even if it only wants to be an R =>. Turning an R => into a T => is doable as long as you have a way to identify the R parts of any T, and ignore the rest. If you know your images are grayscale, just use any of the RGB channels. Therefore, working with R by way of T is easy if both sides are in on it. If only one side is in on it, it's either scraping or SEO.
But neither applies to arbitrary processing blocks T => T that need to mutually interoperate. If A throws away some of the data it received before sending it to B, and then B throws away other parts before sending it back to A, little will be left. For reliable operation, either A → B → A or B → A → B ought to be a clean round-trip. Ideally, both. Just try to tell a user you preserve <100% of their data every time they do something.
Consider interoperating with e.g. Adobe Photoshop. A Photoshop file isn't just an image, it's a collection of image layers, vector shapes, external resources and filters. These are combined into a layer tree, which specifies how the graphics ought to be combined. This can involve arbitrary nesting, with each layer having unique blend modes and overlaid effects. Photoshop's core here acts like a kernel in the OS sense, providing a base data model and surrounding services. It's responsible for maintaining the mixed raster/vector workspace of the layered image. The associated "user space" is the drawing tools and inspectors.
Being mutually compatible with Photoshop means being a PSD => PSD back-end, which is equivalent to re-implementing all the "kernel space" concepts. Changing a single parameter or pixel requires re-composing the entire layer stack, so you must build a kernel or engine that can do all the same things.
Also, let's be honest here. The average contemporary dev eyes legacy desktop software somewhat with suspicion. Sure, it's old and creaky, and their toolbars are incredibly out of fashion. But they get the job done, and come with decades of accumulated, deep customizability. The entrenched competition is stiff.
This reflects what I call the Kernel Problem. If you have a processing kernel revolving around an arbitrary T => T block, then the input T must be more like a program than data. It's not just data and metadata, it's also instructions. This means there is only one correct way to interpret them, aside from differences in fidelity or performance. If you have two such kernels which are fully interoperable in either direction, then they must share the same logic on the inside, at least up to equivalence.
If you are trying to match an existing kernel T => T's features in your S => S, your S must be at least as expressive as their original T. To do more, every T must also be a valid S. You must be the Animal to their Duck, not a Duck to their Animal, which makes this sort of like reverse inheritance: you adopt all their code but can then only add non-conflicting changes, so as to still allow for real substitution. A concrete illustration is what "Linux Subsystem for Windows" actually means in practice: put a kernel inside the kernel, or reimplement it 1-to-1. It's also how browsers evolved over time, by adding, not subtracting.
Therefor, I would argue an "extensible kernel" is in the broad sense an oxymoron, like an "extensible foundation" of a building. The foundation is the part that is supposed to support everything else. Its purpose is to enable vertical extension, not horizontal.
If you expand a foundation without building anything on it, it's generally considered a waste of space. If you try to change a foundation underneath people, they rightly get upset. The work isn't done until the building actually stands. If you keep adding on to the same mega-building, maintenance and renewal become impossible. The proper solution for that is called a town or a city.
Naturally kernels can have plug-ins too, so you can wonder if that's actually a "motte user-land" or not. What's important is to notice the dual function. A kernel should enable and support things, by sticking to the essentials and being solid. At the same time, it needs to also ship with a useful toolset working with a single type T that behaves extensibly: it must support arbitrary programs with access to processes, devices, etc.
If extensibility + time = kitchen sink bloat, how do you counter entropy?
You must anticipate, by designing even your core T itself to be decomposable and hence opt-in à la carte. A true extensible kernel is therefor really a decomposable kernel, or perhaps a kernel generator, which in the limit becomes a microkernel. This applies whether you are talking about Photoshop or Linux. You must build it so that it revolves around an A & B & C & ..., so that both A => A and B => B can work directly on an ABC and implicitly preserve the ABC-ness of the result. If all you need to care about is A or B, you can use them directly in a reduced version of the system. If you use an AB, only its pertinent aspects should be present.
Entity-Component Systems are a common way to do this. But they too have a kernel problem: opting in to a component means adopting a particular system that operates on that type of component. Such systems also have dependency chains, which have to be set up in the right order for the whole to behave right. It is not really A & B but A<B> or B<A> in practice. So in order for two different implementations of A or B to be mutually compatible, they again have to be equivalent. Otherwise you can't replace a Process<T> without replacing all the associated input, or getting unusably different output.
The main effect of à la carte architecture is that it never seems like a good idea to force anyone else to turn their Duck into a Chicken, by adopting all your components. You should instead try to agree on a shared Animal<T>. Any ChickenDuck that you do invent will have a limited action radius. Because other people can decide for themselves whether they truly need to deal with chickens on their own time.
None of this is new, I'm just recapturing old wisdom. It frankly seems weird to use programming terminology to have described this problem, when the one place it is not a big deal is inside a single, comfy programming environment. We do in fact freely import modules à la carte when we code, because our type T is the single environment of our language run-time.
But it's not so rosy. The cautionary tale of Python 2 vs 3: if you mess with the internals and standard lib, it's a different language, no matter how you do it. You still have a kernel everyone depends on and it can take over a decade to migrate a software ecosystem.
Everyone has also experienced the limits of modularity, in the form of overly wrapped APIs and libraries, which add more problems than they solve. In practice, everyone on a team must still agree on one master, built incrementally, where all the types and behavior is negotiated and agreed upon. This is either a formal spec, or a defacto one. If it is refactored, that's just a fork everyone agrees to run with. Again, it's not so much extensible, just perpetually unfinished.
À la carte architecture is clearly necessary but not sufficient on its own. Because there is one more thing that people tend to overlook when designing a schema for data: how a normal person will actually edit the data inside.

Oil and Water
Engineering trumps theoretical models, hence the description of PSD above actually omits one point deliberately.
It turns out, if all you want to do is display a PSD, you don't need to reimplement Photoshop's semantics. Each .PSD contains a pre-baked version of the image, so that you don't need to interpret it. A .PSD is really two file formats in one, a layered PSD and something like a raw PNG. It is not a ChickenDuck but a DuckAnimal. They planned ahead so that the Photoshop format can still work if all you want to be is MSPaint => MSPaint. For example, if you're a printer.
This might lead you to wonder.
Given that PNG is itself extensible, you can imagine a PNG-PSD that does the same thing as a PSD. It contains an ordinary image, with all the Photoshop specific data embedded in a separate PSD section. Wouldn't that be better? Now any app that can read PNG can read PSD, and can preserve the PSD-ness. Except, no. If anyone blindly edits the PNG part of the PNG-PSD, while preserving the PSD data, they produce a file where both are out of sync. What you see now depends on which app reads it. PNG-PSDs would be landmines in a mixed ecosystem.
It's unavoidable: if some of the data in a schema is derived from other data in it, the whole cannot be correctly edited by a "dumb", domain-agnostic editor, because of the Kernel Problem. This is why "single source of truth" should always be the end-goal.
A fully extensible format is mainly just kicking the can down the road, saving all the problems for later. It suggests a bit of a self-serving lie: "Extensibility is for other people." It is a successful business recipe, but a poor engineering strategy. It results in small plug-ins, which are not first class, and not fundamentally changing any baked in assumptions.
But the question isn't whether plug-ins are good or bad. The question is whether you actually want to lock your users of tomorrow into how your code works today. You really don't, not unless you've got something battle-hardened already.

If you do see an extensible system working in the wild on the Input, Process and Output side, that means it's got at least one defacto standard driving it. Either different Inputs and Outputs have agreed to convert to and from the same intermediate language... or different middle blocks have agreed to harmonize data and instructions the same way.
This must either flatten over format-specific nuances, or be continually forked to support every new concept being used. Likely this is a body of practices that has mostly grown organically around the task at hand. Given enough time, you can draw a boundary around a "kernel" and a "user land" anywhere. To make this easier, a run-time can help do auto-conversion between versions or types. But somebody still has to be doing it.
This describes exactly what happened with web browsers. They cloned each other's new features, while web developers added workarounds for the missing pieces. Not to make it work differently, but to keep it all working exactly the same. Eventually people got fed up and just adopted a React-like.
That is, you never really apply extensibility on all three fronts at the same time. It doesn't make sense: arbitrary code can't work usefully on arbitrary data. The input and output need to have some guarantees about the process, or vice versa.
Putting data inside a free-form key/value map doesn't change things much. It's barely an improvement over having a unknownData byte[] mix-in on each native type. It only pays off if you actually adopt a decomposable model and stick with it. That way the data is not unknown, but always provides a serviceable view on its own. Arguably this is the killer feature of a dynamic language. The benefit of "extensible data" is mainly "fully introspectable without recompilation."
The success of JSON is an obvious example here. The limited set of types means it can be round-tripped cleanly into most languages. Despite its shortcomings, it can go anywhere text can, and that includes every text editor too. Some find it distasteful to e.g. encode a number as text, but the more important question is: will anyone ever be editing this number by hand or not?
The issue of binary data can be mitigated with a combo of JSON manifest + binary blob, such as in GLTF 3D models. The binary data is packed arrays, ready for GPU consumption. This is a good example of a practical composition A & B. It lets people reuse both the code and practices they know. The only real 'parsing' needed is the slicing of a buffer at known offsets. It also acts as a handy separation between light-weight metadata and heavy-duty data, useful in a networked environment. The format allows for both to be packed in one file, but it's not required.
For a given purpose, you need a well-defined single type T that sets the ground rules for both data and code, which means T must be a common language. It must be able to work equally well as an A, B and C, which are needs that must have been anticipated. Yet it should be built such that you can just use a D of your own, without inconvenient dependency. The key quality to aim for is not creativity but discipline.
If you can truly substitute a type with something else everywhere, it can't be arbitrarily extended or altered, it must retain the exact same interface. In the real world, that means it must actually do the same thing, only marginally better or in a different context. A tool like ffmpeg only exists because we invented a bajillion different ways to encode the same video, and the only solution is to make one thing that supports everything. It's the Unicode of video.
If you extend something into a new type, it's not actually a substitute, it's a fork trying to displace the old standard. As soon as it's used, it creates a data set that follows a new standard. Even when you build your own parsers and/or serializers, you are inventing a spec of your own. Somebody else can do the same thing to you, and that somebody might just be you 6 months from now. Being a programmer means being an archivist-general for the data your code generates.
* * *
If you actually think about it, extensibility and substitution are opposites in the design space. You must not extend, you must decompose, if you wish to retain the option of substituting it with something simpler yet equivalent for your needs. Because the other direction is one-way only, only ever adding complexity, which can only be manually refactored out again.
If someone is trying to sell you on something "extensible," look closely. Is it actually à la carte? Does it come with a reasonable set of proven practices on how to use it? If not, they are selling you a fairy tale, and possibly themselves too. They haven't actually made it reusable yet: if two different people started using it to solve the same new problem, they would not end up with compatible solutions. You will have 4 standards: the original, the two new variants, and the attempt to resolve all 3.
Usually it is circumstance, hierarchy and timing that decides who adapts their data and their code to whom, instead of careful consideration and iteration. Conway's law reigns, and most software is shaped like the communication structure of the people who built it. "Patch," "minor" or "major" release is just the difference between "Pretty please?", "Right?" and "I wasn't asking."
We can do a lot better. But the mindset it requires at this point is not extensibility. The job at hand is salvage.
If you want a concise example of how to do this right, check out Lottie. It's an animation system for the web, which is fed by an Adobe AfterEffects export plug-in. This means that animators can use the same standard tools they are familiar with. The key trick here is to reduce complex AfterEffects data to a much simpler animation model: that of eased bezier curves. Not all of AfterEffects' features are supported, but all the essentials do work. So Lottie is a Bezier => Bezier back-end, fed by an AfterEffects => Bezier converter.
It's so sensible, that when I was asked how to build an animation system in Rust, I suggested doing exactly the same thing. So we did.