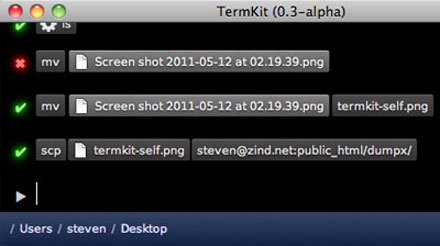
On TermKit
I've been administering Unix machines for many years now, and frankly, it kinda sucks. It makes me wonder, when sitting in front of a crisp, 2.3 million pixel display (i.e. a laptop) why I'm telling those pixels to draw me a computer terminal from the 80s.
And yet, that's what us tech nerds do every day. The default Unix toolchain, marked in time by the 1970 epoch, operates in a world where data is either binary or text, and text is displayed in monospace chunks. The interaction is strictly limited to a linear flow of keystrokes, always directed at only one process. And that process is capable of communicating only in short little grunts of text, perhaps coalescing into a cutesy little ASCII art imitation of things that grown-ups call "dialogs", "progress bars", "tables" and "graphs".
The Unix philosophy talks about software as a toolset, about tiny programs that can be composed seamlessly. The principles are sound, and have indeed stood the test of time. But they were implemented in a time when computing resources were orders of magnitude smaller, and computer interaction was undiscovered country.
In the meantime, we've gotten a lot better at displaying information. We've also learned a lot of lessons through the web about data interchange, network transparency, API design, and more. We know better how small tweaks in an implementation can make a world of difference in usability.
And yet the world of Unix is rife with jargon, invisible processes, traps and legacy bits. Every new adept has to pass a constant trial by fire, of not destroying their system at every opportunity it gives them.
So while I agree that having a flexible toolbox is great, in my opinion, those pieces could be built a lot better. I don't want the computer equivalent of a screwdriver and a hammer, I want a tricorder and a laser saw. TermKit is my attempt at making these better tools and addresses a couple of major pain points.
I see TermKit as an extension of what Apple did with OS X, in particular the system tools like Disk Utility and Activity Monitor. Tech stuff doesn't have to look like it comes from the Matrix.
Rich Display
It's 2011, and monospace text just doesn't cut it anymore. In the default ANSI color palette, barely any of the possible color combinations are even readable. We can't display graphs, mathematical formulas, tables, etc. We can't use the principles of modern typography to lay out information in a readable, balanced way.
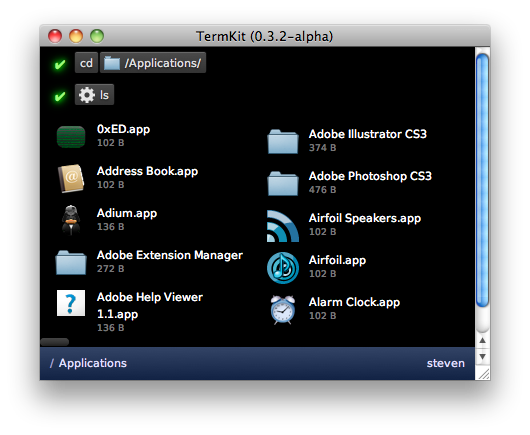
So instead, I opted for a front-end built in WebKit. Programs can display anything that a browser can, including HTML5 media. The output is built out of generic widgets (lists, tables, images, files, progress bars, etc.). The goal is to offer a rich enough set for the common data types of Unix, extensible with plug-ins. The back-end streams display output to the front-end, as a series of objects and commands.
I should stress that despite WebKit it is not my intent to make HTML the lingua franca of Unix. The front-end is merely implemented in it, as it makes it instantly accessible to anyone with HTML/CSS knowledge.
Pipes
Unix pipes are anonymous binary streams, and each process comes with at least three: Standard In, Standard Out and Standard Error. This corresponds to the typical Input > Processing > Output model, with an additional error channel. However, in actual usage, there are two very different scenarios.
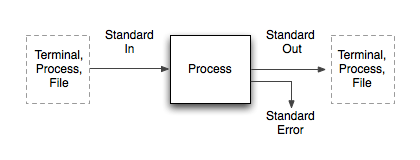
One is the case of interactive usage: a human watches the program output (from Std Out) on a display, and types keystrokes to interact with it (into Std In). Another case is the data processing job: a program accepts a data stream in a particular format on Std In, and immediately outputs a related data stream on Std Out. These two can be mixed, in that a chain of piped commands can have a human at either end, though usually this implies non-interactive operation.
These two cases are shoehorned into the same pipes, but happen quite differently. Human input is spontaneous, sporadic and error prone. Data input is strictly formatted and continuous. Human output is ambiguous, spaced out and wordy. Data output is conservative and monolithic.
As a result, many Unix programs have to be careful about data. For example, many tools dynamically detect whether they are running in interactive mode, and adjust their output to be more human-friendly or computer-friendly. Other tools come with flags to request the input/output in specific formats.
This has lead to "somewhat parseable text" being the default interchange format of choice. This seems like an okay choice, until you start to factor in the biggest lesson learned on the web: there is no such thing as plain text. Text is messy. Text-based formats lie at the basis of every SQL injection, XSS exploit and encoding error. And it's in text-parsing code where you'll likely find buffer overflows.
What this means in practice is that in every context, there are some forbidden characters, either by convention or by spec. For example, no Unicode or spaces in filenames. In theory, it's perfectly fine, but in practice, there's at least one shell script on your system that would blow up if you tried. Despite the promise of text as the universal interchange format, we've been forced to impose tons of vague limits.
So how do we fix this? By separating the "data" part from the "human" part. Then we can use messy text for humans, and pure data for the machines. Enter "Data In/Out", "View In/Out".
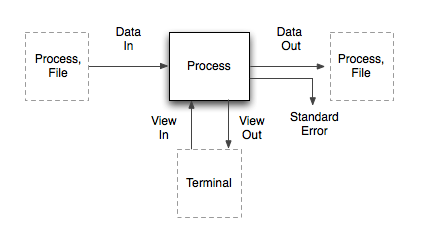
The data pipes correspond to the classical Std pipes, with one difference: the stream is prefixed with MIME-like headers (Content-Type, Content-Length, etc). Of these, only the 'Content-Type' is required. It allows programs to know what kind of input they're receiving, and handle it graciously without sniffing. Aside from that, the data on the pipe is a raw binary stream.
The view pipes carry the display output and interaction to the front-end. Widgets and UI commands are streamed back and forth as JSON messages over the view pipes.
The real magic happens when these two are combined. The last dangling Std Out pipe of any command chain needs to go into the Terminal, to be displayed as output. But the data coming out of Data Out is not necessarily human-friendly.
Thanks to the MIME-types, we can solve this universally. TermKit contains a library of output formatters which each handle a certain type of content (text, code, images, ...). It selects the right formatter based on the Content-Type, which then generates a stream of view updates. These go over the View Out pipe and are added to the command output.
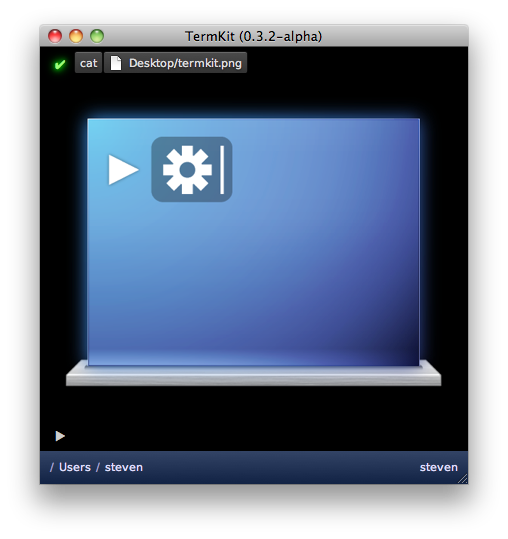
As a result, you can cat a PNG and have it just work. TermKit cat doesn't know how to process PNGs or HTML—it only guesses the MIME type based on the filename and pipes the raw data to the next process. Then the formatter sends the image to the front-end. If you cat a source code file, it gets printed with line numbers and syntax highlighting.
So where does "somewhat parseable text" fit in? It turns out to be mostly unnecessary. Commands like ls output structured data by nature, i.e. a listing of files from one or more locations. It makes sense to pipe around this data in machine-form. Output flags like ls -l become mere hints for the final display, which can toggle on-the-fly between compact and full listing.
In TermKit's case, JSON is the interchange format of choice. The Content-Type for file listings is application/json; schema=termkit.files. The schema acts as a marker to select the right output plug-in. In this case, we want the file formatter rather than the generic raw JSON formatter.
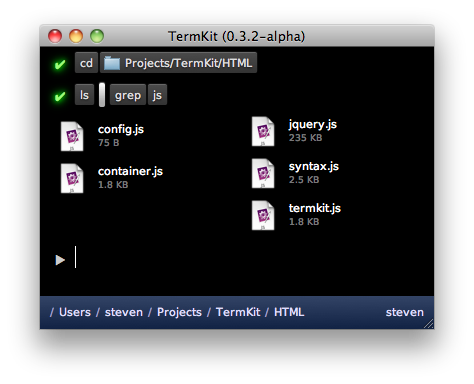
Isn't JSON data harder to work with than lines of text? Only in some ways, but parsing JSON is trivial these days in any language. Because of this, I built TermKit grep so it supports grepping JSON data recursively. This happens transparently when the input is application/json instead of text/plain. As a result ls | grep works as you'd expect it to.
To slot in traditional Unix utilities in this model, we can pipe their data as application/octet-stream to start with, and enhance specific applications with type hints and wrapper scripts.
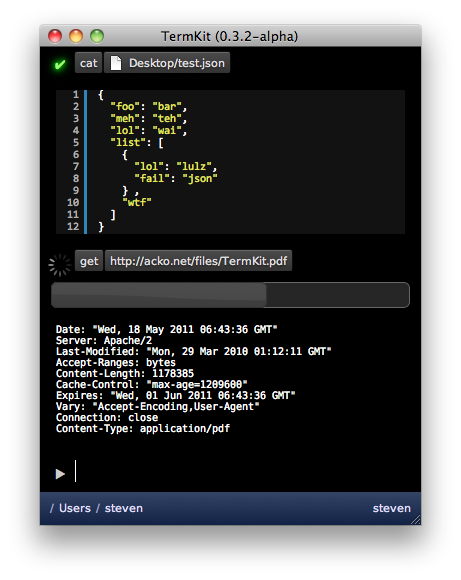
Finally, having type annotations on pipes opens up another opportunity: it allows us to pipe in HTTP GET / POST requests almost transparently. Getting a URL becomes no different from catting a file, and both can have fancy progress bars, even when inside a pipe chain like get | grep.
Synchronous interaction
All interaction in a traditional terminal is synchronous. Only one process is interactive at a time, and each keystroke must be processed by the remote shell before it is displayed. This leads to an obvious daily frustration: SSH keystroke lag.
To fix this, TermKit is built out of a separate front-end and back-end. The front-end can run locally, controlling a back-end on a remote machine. The connection can be tunneled over SSH for security.
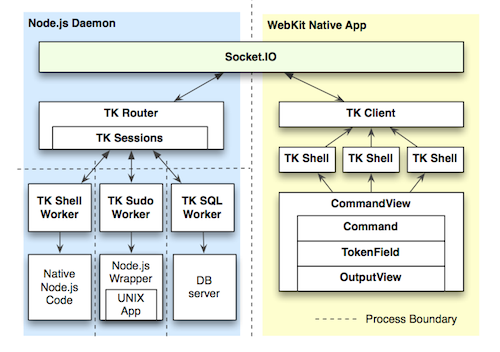 Architecture diagram (TK stands for TermKit)
Architecture diagram (TK stands for TermKit)
Additionally, all display updates and queries are asynchronous. The WebKit-based HTML display is split up into component views, and the view pipes of each subprocess are routed to their own view. Vice-versa, any interactive widgets inside a view can send callback messages back to their origin process, as long as it's still running.
This also allows background processes to work without overflowing the command prompt.
String-based command line
A lot of my frustration comes from bash's arcane syntax. It has a particularly nasty variant of C-style escaping. Just go ahead and try to match a regular expression involving both types of quotes.
But at its core, a bash command is a series of tokens. Some tokens are single words, some are flags, some are quoted strings, some are modifiers (like | and >). It makes sense for the input to reflect this.
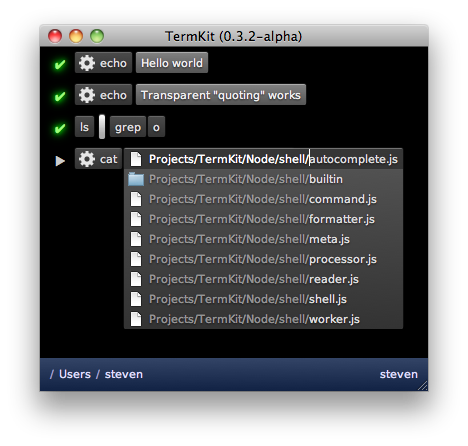
TermKit's input revolves around tokenfield.js, a new snappy widget with plenty of tricks. It can do auto-quoting, inline autocomplete, icon badges, and more. It avoids the escaping issue altogether, by always processing the command as tokens rather than text. Keys that trigger special behaviors (like a quote) can be pressed again to undo the behavior and just type one character.
The behaviors are encoded in a series of objects and regexp-based triggers, which transform and split tokens as they are typed. That means it's extensible too.
Usability
At the end of the day, Unix just has bad usability. It tricks us with unnecessary abbreviations, inconsistent arguments (-r vs -R) and nitpicky syntax. Additionally, Unix has a habit of giving you raw data, but not telling you useful facts, e.g. 'r-xr-xr-x' instead of "You can't touch this" (ba-dum tsshh).
One of the Unix principles is nobly called "Least Surprise", but in practice, from having observed new Unix users, I think it often becomes "Maximum Confusion". We should be more pro-active in nudging our users in the right direction, and our tools should be designed for maximum discoverability.
For example, I want to see the relevant part of a man page in a tooltip when I'm typing argument switches. I'd love for dangerous flags to be highlighted in red. I'd love to see regexp hints of possible patterns inline.
There's tons to be done here, but we can't do anything without modern UI abilities.
Focus and Status
With a project like TermKit, it's easy to look at the shiny exterior and think "meh", or that I'm just doing things differently for difference's sake. But to me, the real action is under the hood. With a couple of tweaks and some uncompromising spring cleaning, we can get Unix to do a lot more for us.
The current version of TermKit is just a rough alpha, and what it does is in many ways just parlour tricks compared to what it could be doing in a few months. The architecture definitely supports it.
I've worked on TermKit off and on for about a year now, so I'd love to hear feedback and ideas. Please go check out the code.
TermKit owes its existence to Node.js, Socket.IO, jQuery and WebKit. Thanks to everyone who has contributed to those projects.
Edit, a couple of quick points:
- A Linux port will definitely happen, since it's built out of WebKit and Node.js. Whoever does it first gets a cookie.
- TermKit is not tied to JSON except in its own internal communication channels. TermKit Pipes can be in any format, and old-school plain-text still works. JSON just happens to be very handy and very lightweight.
- The current output is just a proof of concept and lacks many planned usability enhancements. There are mockups on github.
- If you're going to tell me I'm stupid, please read all the other 100 comments doing so first, so we can keep this short for everyone else.
Edit, random fun:
Someone asked for AVS instead of TermKit in the comments... best I could do was JS1K with a PDF surprise: